Announcing Gimlet's Series A Raise
- Published on
- Authors

- Name
- Zain Asgar

- Name
- Michelle Nguyen

- Name
- Omid Azizi

- Name
- James Bartlett

- Name
- Natalie Serrino
Announcing Gimlet's Series A Raise
Today, we're announcing our $80M Series A raise, led by Menlo Ventures and joined by Eclipse, Factory, Prosperity7, and Triatomic.
Gimlet is an inference cloud designed to run agents. Since our launch 5 months ago, the company has seen record demand. Our customer base has tripled and now includes a top frontier lab and a hyperscaler. We're grateful to have the opportunity to run proprietary frontier models on our infrastructure, as these workloads are not typically entrusted to inference providers.
We founded Gimlet out of the belief that AI inference would become the decade's defining infrastructure challenge. That challenge has become even more urgent with the rise of agentic workloads.
Today, the AI industry is in the middle of what we internally refer to as the Inference Speed Wars. Model providers are spending billions reducing agent latency, because agents are increasingly on the critical path of our workflows, and they produce orders of magnitude more tokens than traditional chat models. Coding agents, for example, ingest entire codebases and latency compounds quickly. As agents increasingly communicate with other agents rather than humans, speed matters even more: agents can consume and act on information as fast as you can serve it.
Chat models: what current infrastructure is designed for.
As the need for high-throughput, low-latency agent serving grows, the homogeneous infrastructure these workloads run on today is hitting a wall. Even the largest players face scarcity in both power and chip supply, and brute-force scaling on GPUs alone isn't viable anymore.
Inference is a fundamentally heterogeneous workload. Its different phases, such as prefill, decode, dense attention, and sparse attention, each have different bottlenecks and performance characteristics. Some of these phases map well to GPUs, but others are better suited for entirely different architectures.
Agents are even more heterogeneous than that, because an agent doesn't just run one inference pass. Agents chain multiple models and modalities, call external tools, execute code, and retrieve data, each with its own compute profile. The agentic workload is far more varied than any single inference pass, and inefficiencies compound with every step in the agentic graph.
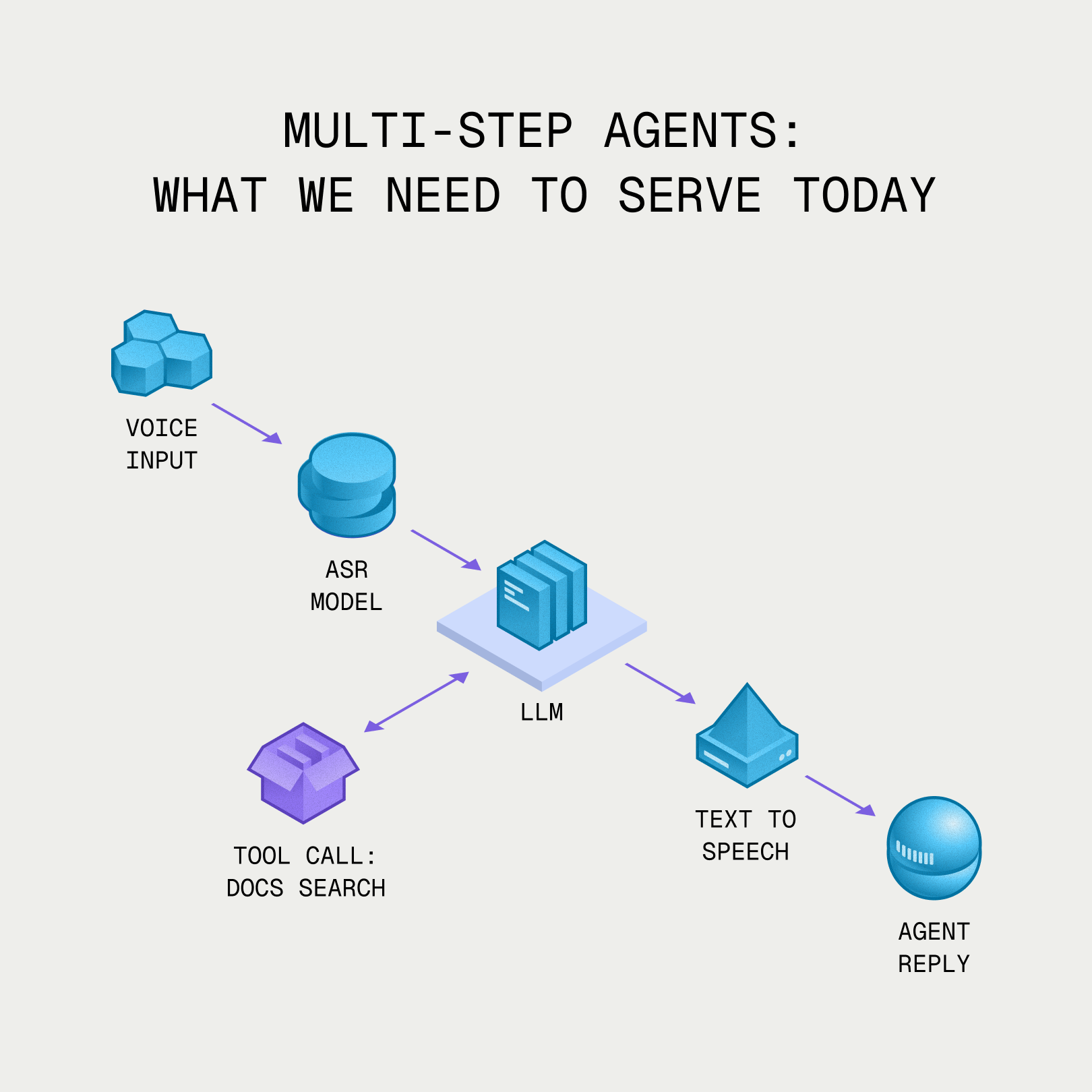
Multi-step agents: what we need to serve today.
Rather than building an inference stack on status quo infrastructure (homogeneous GPUs), we designed Gimlet with hardware heterogeneity at its core. This meant building out a software stack that orchestrates complex agentic workloads across heterogeneous hardware, and a new kind of data center to physically connect the hardware together. So far, the result is 3-10X speedups on >1T parameter frontier models with large context windows, within the same power envelope.
Delivering these performance breakthroughs also requires significant investment in physical infrastructure. We're building a new type of datacenter that connects accelerators that have never coexisted before over high-speed networks. To do this, we've encountered challenges we didn't originally anticipate, requiring creative solutions from ways to connect hardware that was never designed to talk to each other, to managing different thermal profiles across mixed architectures and literal plumbing. The demands of inference are reinventing the entire physical datacenter.
As agents grow and become more complex, the need for heterogeneous infrastructure only grows. Today's agents are doing things that seemed impossible even a few years ago, and will continue to evolve for the foreseeable future. It's incredibly exciting to develop the infrastructure to make these agents faster and therefore more useful.
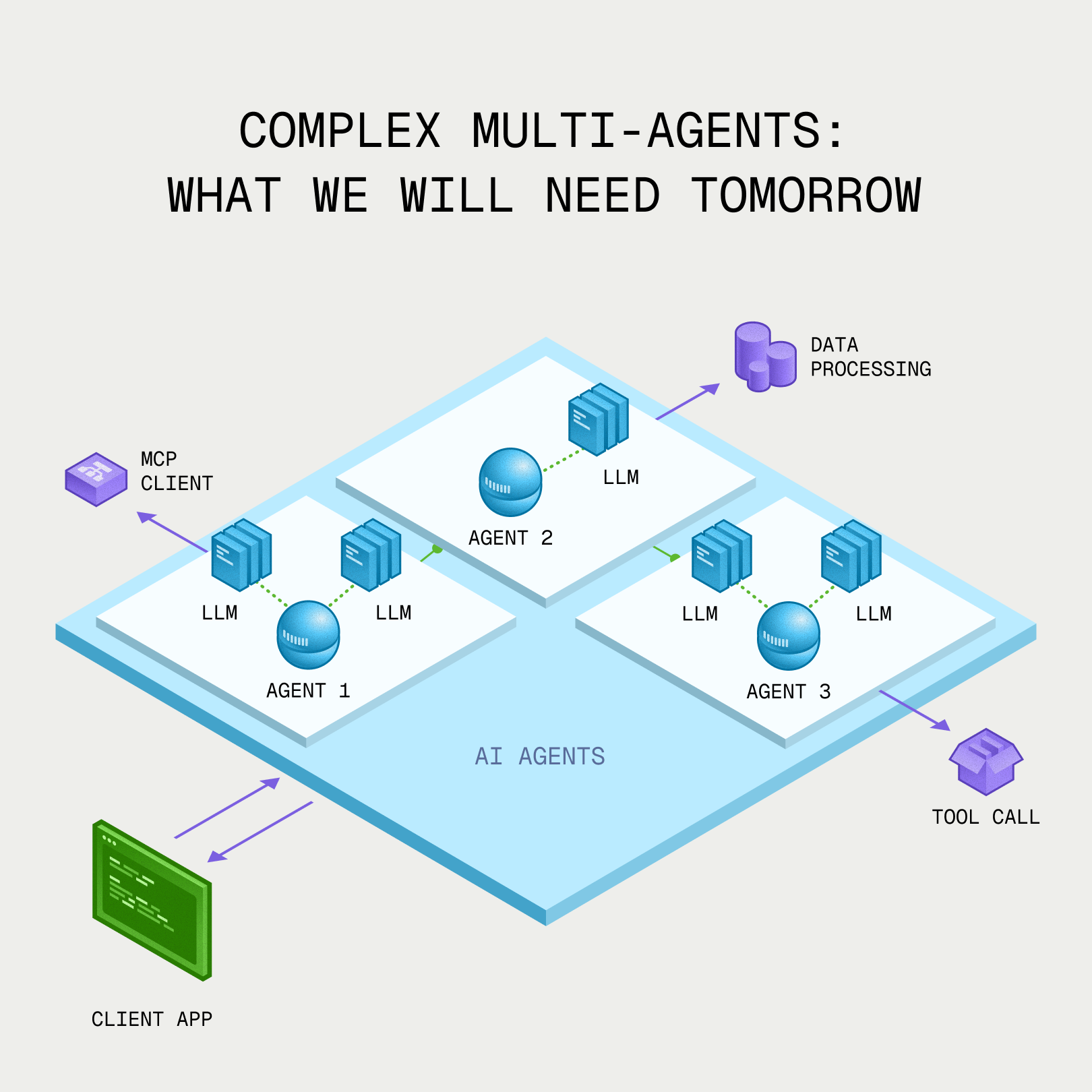
Complex multi-agents: what we will need tomorrow.
Thank you again to our investors and also to our angels for believing in the mission from the beginning. If you agree that the future of AI inference is heterogeneous and want to get in touch, you can reach us here: