Low-Latency Inference with Speculative Decoding on d-Matrix Corsair and GPU
- Published on
- Authors

- Name
- James Bartlett

- Name
- Natalie Serrino

- Name
- Zain Asgar

- Name
- Sudeep Bhoja

- Name
- Prashant Nair

- Name
- Nikhil Ghanathe

- Name
- Nithesh Kurella
Low-Latency Inference with Speculative Decoding on d-Matrix Corsair and GPU
tl;dr: We evaluated running gpt-oss-120b with a 1.6B parameter speculative decoder on d-Matrix Corsair. Compared to the same speculative decoder on GPU and equivalent energy consumption, we've found that the Corsair-based solution delivers 2-5X end-to-end request speedup on configurations optimized for interactivity, and up to 10X end-to-end speedup for energy-optimized configurations.
Introduction
Today, model providers are racing to reduce inference latency while simultaneously scaling to serve surging demand. A core challenge is that most inference infrastructure is typically built around a single hardware architecture, while inference itself is inherently heterogeneous (some phases are very compute intensive, others are memory bandwidth heavy, while others might be network bound). As we discussed in our previous post on SRAM-centric chips, it's difficult to serve all phases of inference well on a single category of hardware.
At Gimlet, we operate an agent-native inference cloud designed to deliver step-change performance for agentic workloads by disaggregating workloads across GPUs, SRAM-centric chips, other accelerators, and CPUs. We do this by partnering with hardware companies and mapping each phase of inference to the best-suited hardware.
In this post, we show one concrete example of that broader idea: offloading speculative decoding (a memory bandwidth sensitive inference stage) from a GPU to the d-Matrix Corsair while serving gpt-oss-120b as the target model. We find this delivers a 2-10X reduction in end-to-end request latency versus running the same speculative decoder on GPU, materially improving end-to-end request time and user experience. For example, a request that previously took 20 seconds could fall to 10s with a 2X speedup and 2s at 10X.

View of the d-Matrix Corsair card, which contains 2GB of SRAM in a single card.
d-Matrix's Corsair is an SRAM-centric AI accelerator designed for low-latency inference by pairing compute with a large pool of on-chip memory. A single Corsair card contains a whopping 2GB of on-chip SRAM and delivers up to 150 TB/s memory bandwidth - making it especially interesting for memory bandwidth sensitive inference stages. In this analysis, we use Corsair to run a speculative decoder, and we are also actively evaluating it for other phases of inference such as decode.
Quick Refresher on Speculative Decoding
As discussed in our previous post, prefill is compute-intensive and highly efficient on GPUs, whereas decode is memory-bound, making it a worse fit for GPUs. To make matters worse, decode is auto-regressive - computation for the next token cannot begin until the previous token finishes - so users must wait for each of their tokens to be computed sequentially.
Speculative decoding improves inference performance by shortening the auto-regressive decode phase. This post focused on draft-model speculative decoding, but related methods such as EAGLE are also part of the same family of approaches. In draft-model speculative decoding, a smaller model makes predictions about tokens, which are then verified in batch by the larger, target model. The core insight is that it's faster to verify a set of N tokens on the larger target model than it is to predict them one by one, as long as the draft model is able to guess right with a high enough frequency.
The effectiveness of speculative decoding depends on how good the draft model is at predicting tokens for the target model. This accuracy will generally improve as the draft model gets bigger - but a bigger draft model is also slower, which reduces the benefits of doing speculative decoding in the first place.
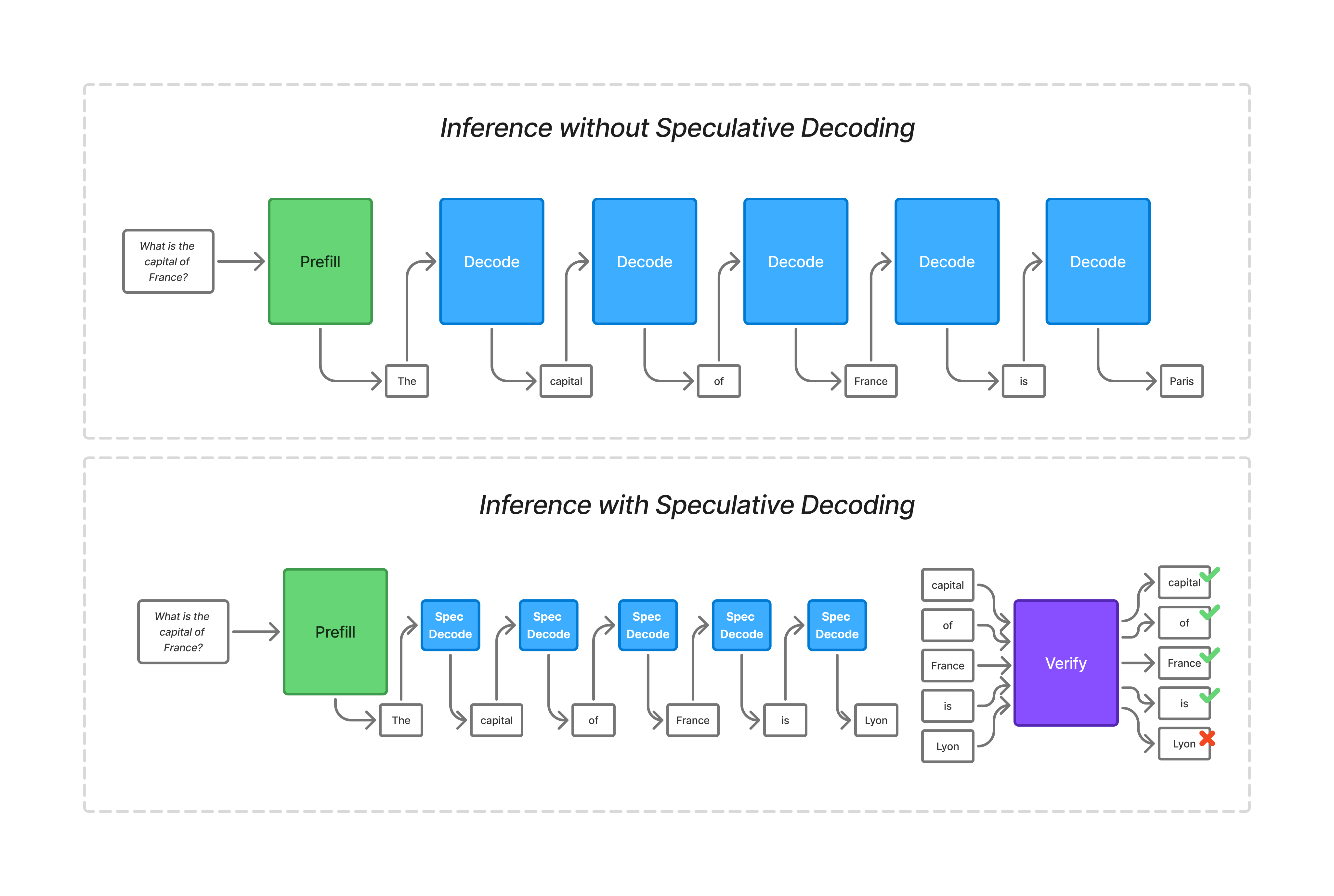
Inference with and without speculative decoding. With speculative decoding, the draft model makes predictions on the next token, which are then verified in batch by the target model. Since the speculative decode model is small, and the verification can be done on multiple tokens at once, this helps shift the workload to be more compute bound.
Verification checks drafted tokens in batch, and only keeps the valid token sequence. Once a token is rejected, all subsequent tokens are discarded, even if they would have been correct individually. This means that longer draft sequences see lower acceptance rates, because each token in the sequence is a potential failure point. That tradeoff makes drafting speed especially important, because the cost of failed speculation is lower when it takes less time to create the draft.
When using speculative decoding, the prefill phase is compute-bound, the verify phase becomes more and more compute-bound as the draft sequence gets longer, but the draft phase is memory-bound. This makes the draft phase a good target for a different hardware type.
Benchmarking Methodology
For this analysis, we were interested in evaluating 3 specific scenarios:
- A homogeneous, disaggregated prefill-decode setup, running both phases on GPU
- A homogeneous speculative decoding setup, running the prefill, speculative decode, and verify phases all on GPUs
- A heterogeneous speculative decoding setup, running the prefill and verify phases on GPU and the speculative decode phase on d-Matrix Corsair
We used gpt-oss-120b as the target model, and a 1.6B parameter draft model derived from the same architecture. We were interested in modeling a coding workflow, and used an input sequence length of 8K and an output sequence length of 1K tokens. Note that we used a combination of measured and modeled data to produce these results.
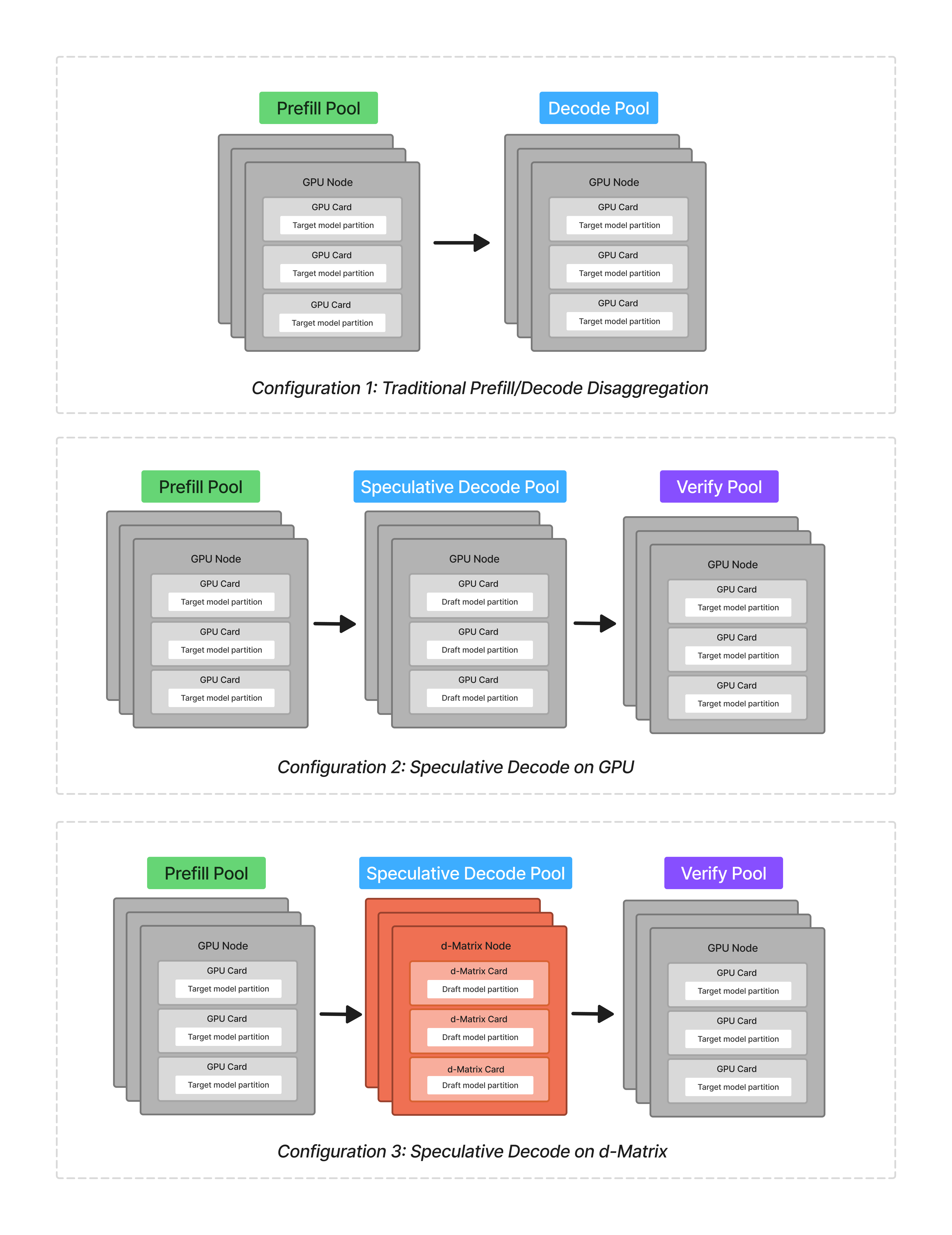
We tested 3 configurations in this analysis: two homogeneous setups on GPUs, and one heterogeneous setup incorporating the d-Matrix Corsair for the speculative decoding phase.
The d-Matrix Corsair is well suited for this workload:
- Each card has 2 GB of on-chip SRAM with 150 TB/s of memory bandwidth (~20X the memory bandwidth of high-end GPUs), making it a good fit for memory-intensive phases like speculative decode.
- It is air-cooled and rack-compatible, which makes it easier to deploy alongside existing infrastructure.
The 1.6B parameter draft model can be deployed on just 2 Corsair cards. This makes speculative decoding an especially attractive first target, because the workload comfortably fits on a single dual-card deployment. We are also evaluating a pure decode offload onto Corsair, which requires more cards because SRAM-architectures keep model weights in on-chip memory for to deliver low-latency performance.
We evaluated many different configurations, varying batch size, number of partitions per phase, and target number of tokens verified at once. We account for networking latency: Regardless of the hardware, each phase runs in a separate node pool within the same scale-out network, and models always partitioned within a single node's scale-up network.
We treat speculative decoding acceptance as a variable, held constant across both speculative decoder configurations (GPU-based and Corsair-based). These acceptance rates vary depending on use case, and we are modeling a coding workflow here with a high acceptance rate (acceptance rates are typically lower than these for non-coding workflows). The draft model is typically fine-tuned on the use case and input distribution.
| Draft Sequence Length | Tokens accepted | Per token acceptance rate |
|---|---|---|
| 5 | 4 | 92.6% |
| 10 | 7 | 93.4% |
| 20 | 12 | 94.8% |
| 40 | 20 | 96.2% |
Results and Analysis
For this analysis, we wanted to isolate separate performance benefits:
- The benefit of moving from pure prefill/decode disaggregation to using speculative decoding
- The benefit of running the speculative decoder on d-Matrix compared to a GPU
Looking at the evaluated scenarios (varying batch size and model parallelism), we can see that the speculative decoding on GPU case outperforms the pure PD disaggregation on throughput/kW versus throughput/user. Because we're comparing across different hardware types, we normalize on throughput/kW rather than throughput/GPU. We compare against a latest-generation GPU from a major hardware provider, with the exact SKU omitted, since the point of the comparison is the architectural tradeoff of using specialized hardware for different phases of inference.
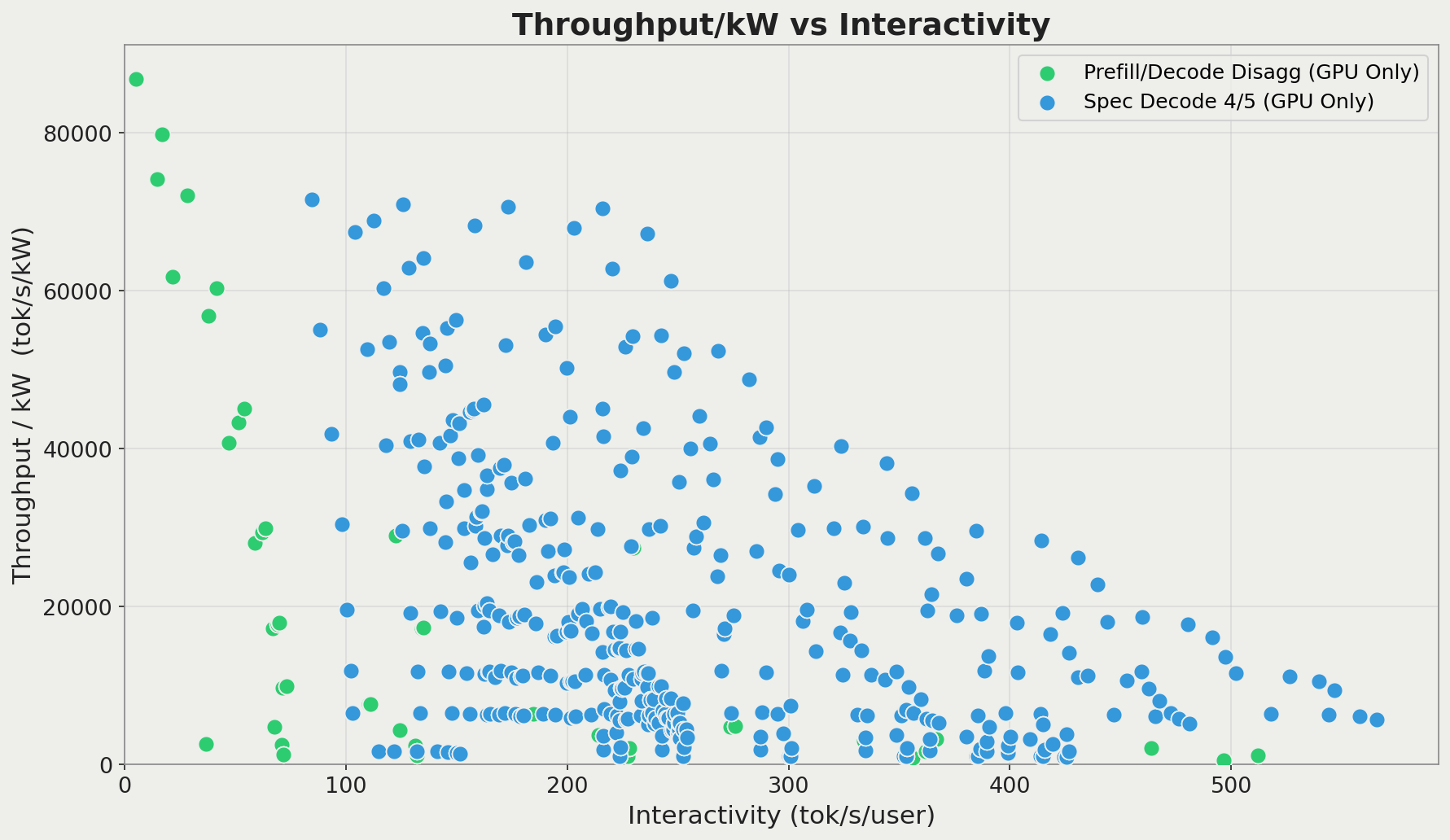
Results from two homogeneous GPU-based systems: prefill/decode disaggregation only using the target model, and speculative decoding using a draft model with 4 of 5 tokens accepted per verify run.
This is a bit easier to see if we limit data points only to the Pareto frontier, which are the configurations that would be used in production:
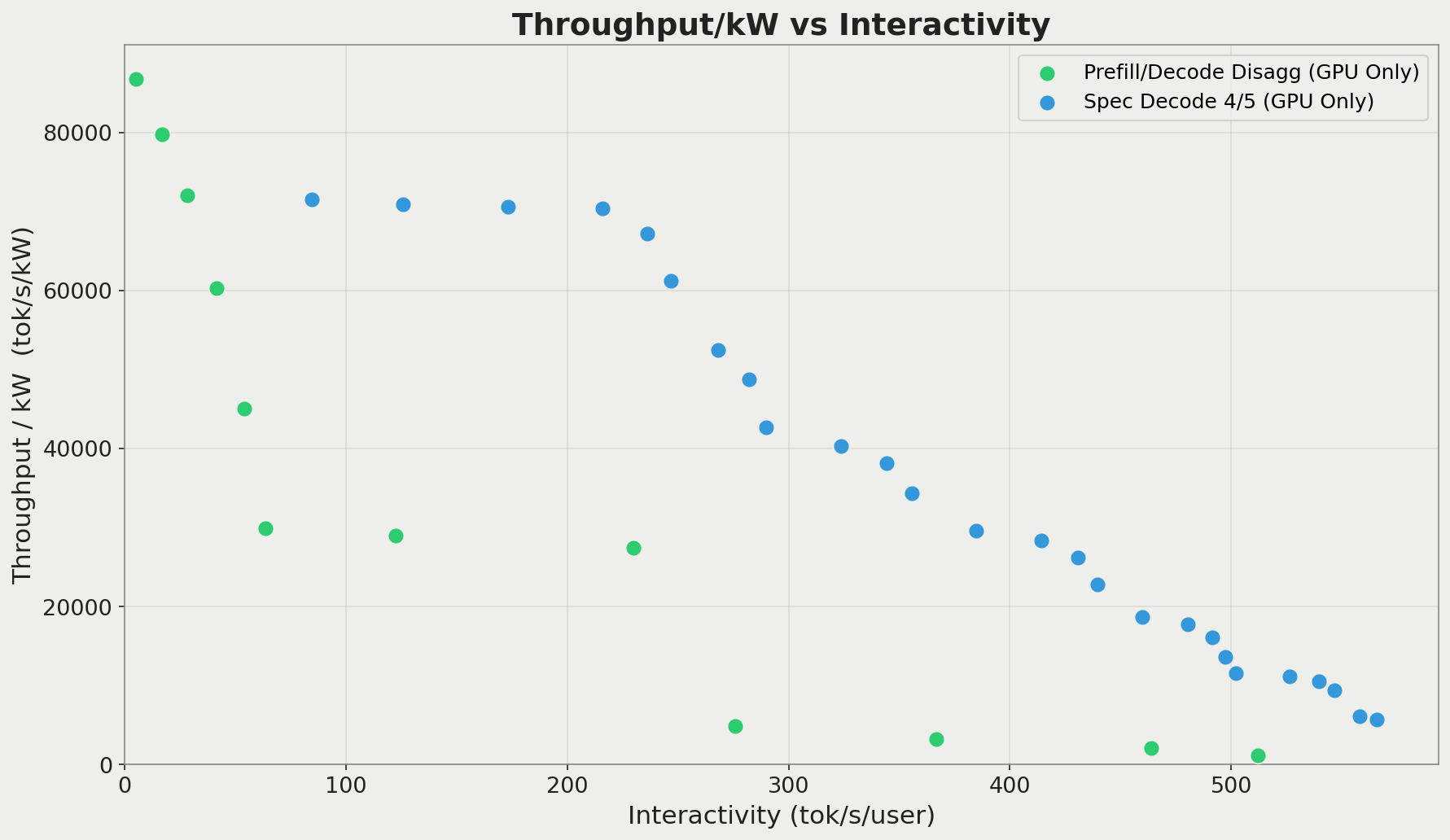
The same results as the prior chart, but limited to only the Pareto frontier points for each configuration. We see that the speculative decoder results in a significant rightward shift (performance improvement) on the Pareto frontier over pure prefill/decode disaggregation.
This aligns with findings from the EAGLE authors, although we don't use EAGLE here: Speculative decoding can produce throughput and latency gains of about 2-5X. Running the same speculative decoder on d-Matrix Corsair produces even more impressive results:
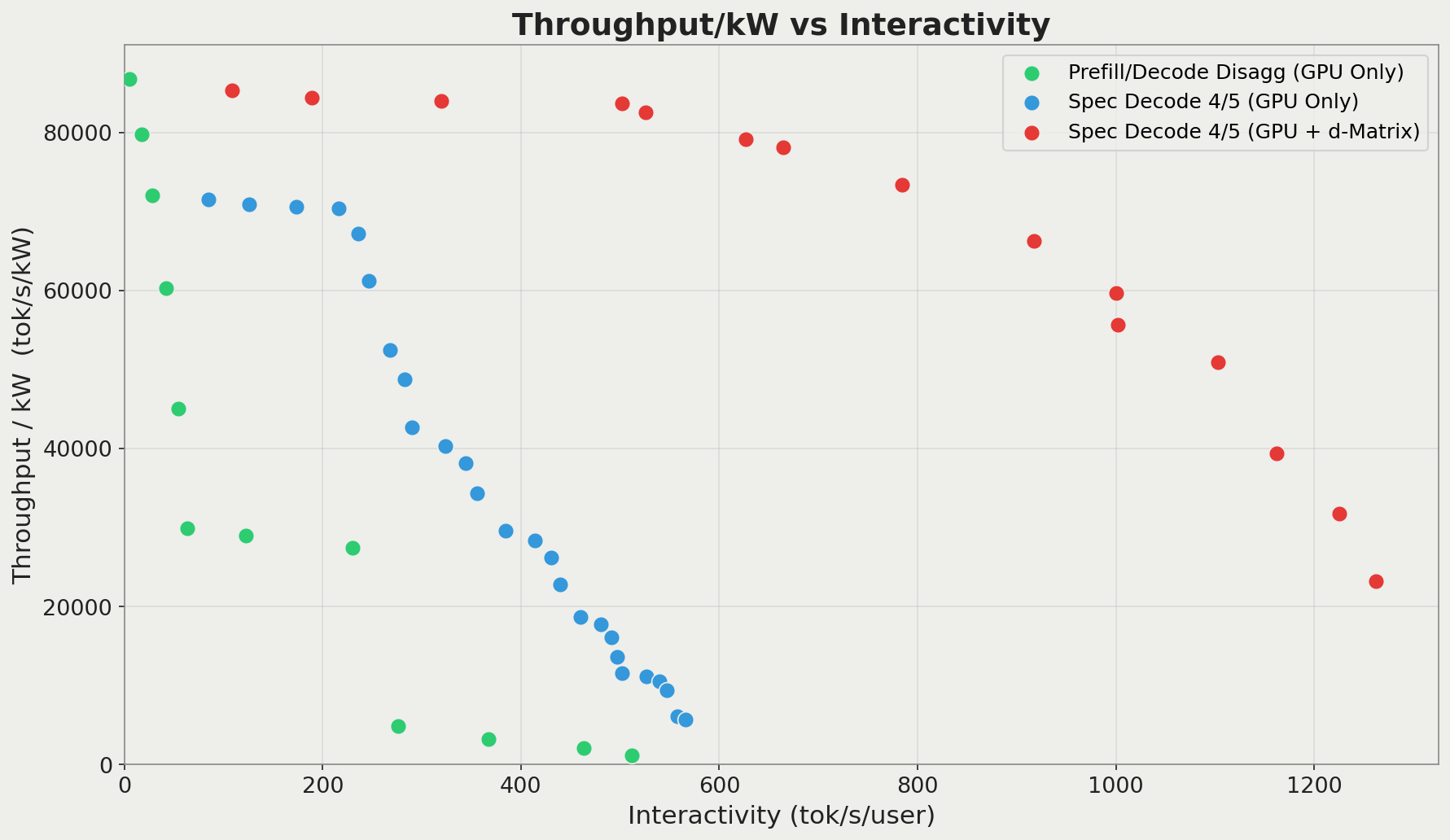
Throughput/kW versus interactivity for all 3 evaluated configurations, for a verify stage of 5 tokens. We can see that running the speculative decoder on d-Matrix and prefill/verify stages on GPU results in very high interactivity for the same power envelope as the other two configurations.
The performance benefit increases when we verify more tokens per step. Longer draft sequences are typically penalized, because each token takes time to produce, but also increase the odds that all subsequent tokens will be rejected. However, since the Corsair can draft tokens so quickly, the cost of those rejected tokens shrinks. This means that you can afford to draft more aggressively and benefit from the rounds where more tokens are accepted. Alternatively, you could run a bigger (and therefore more accurate) draft model on Corsair with the same latency achieved by a smaller model on GPU.
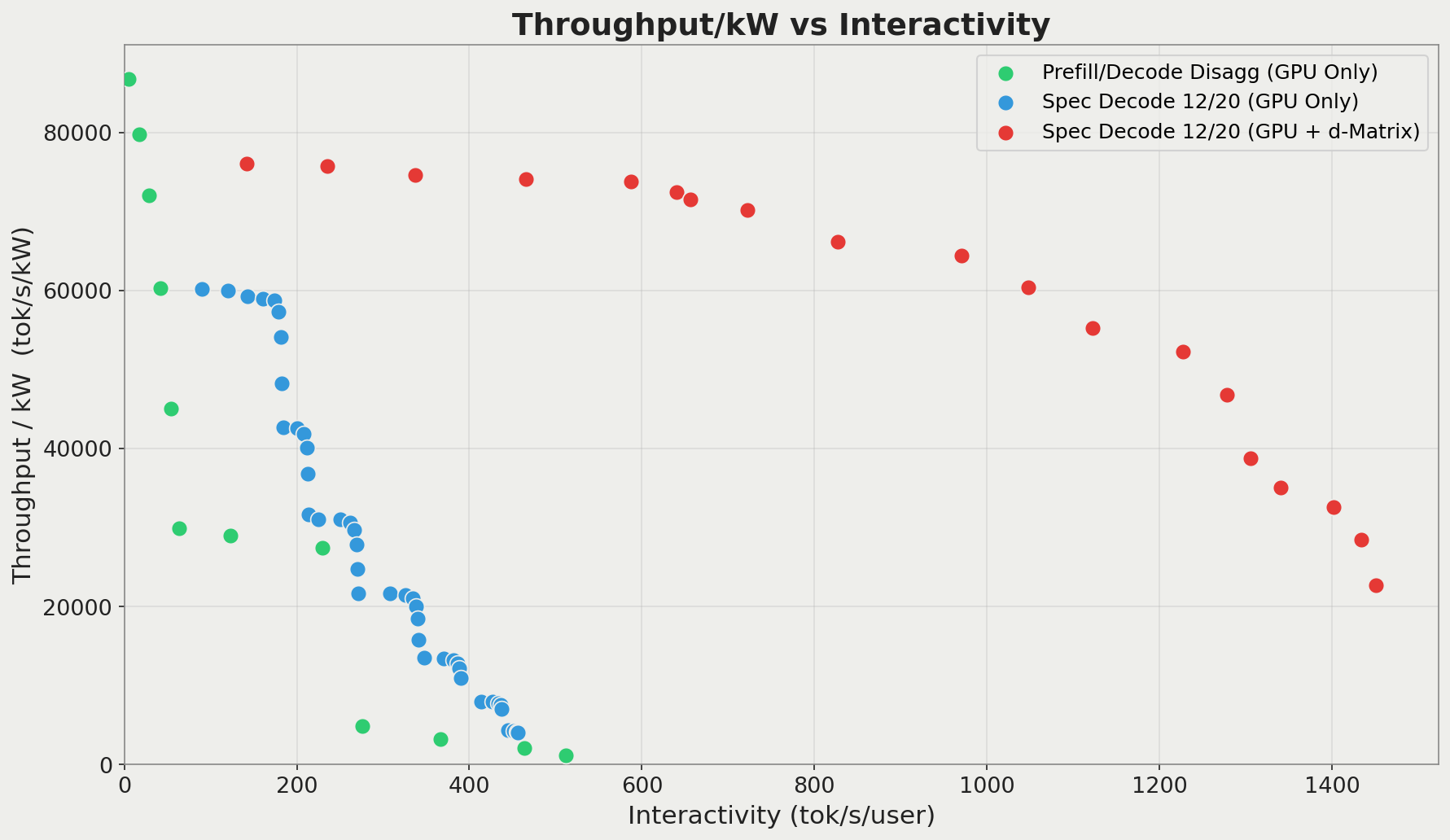
Throughput/kW versus interactivity for all 3 evaluated configurations, for a verify stage of 20 tokens. The benefits of running speculative decoding on the d-Matrix Corsair increase when the verify stage verifies more tokens.
By adding d-Matrix to our setup, we can get a more globally optimal inference setup. Depending on your optimization target, offloading speculative decode to d-Matrix can deliver 2-10X better interactivity for the same energy efficiency, or significantly better throughput/kW at the same interactivity.
For example, consider the improvement in interactivity when energy efficiency is held constant at ~60k tokens/s/kW.
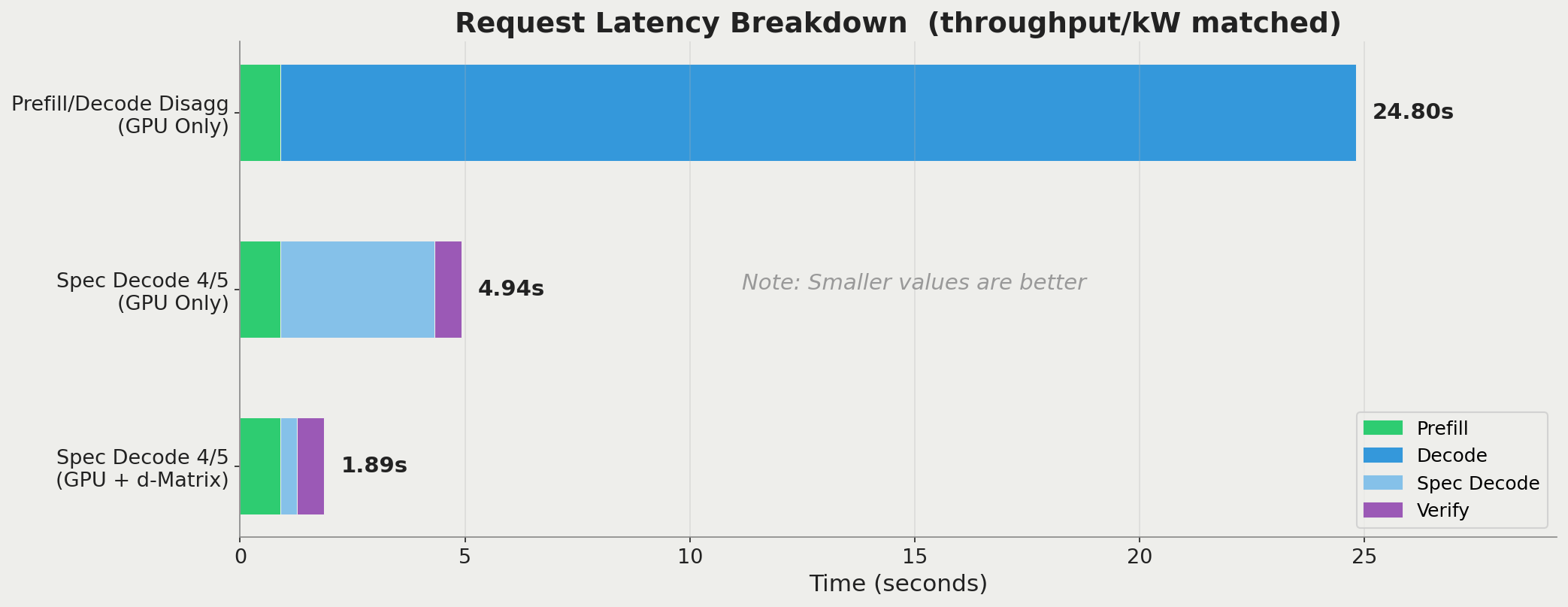
Request latency breakdown for 3 configurations, given a fixed throughput/kW. User-facing request latency goes from 25s to more than 5X faster by adopting the homogeneous speculative decoding setup. Then, another 2.6X benefit on top of that is delivered by incorporating the Corsair to run the speculative decoder. Note that network latency between phases is tacked on to per-phase latency, not excluded.
Conclusion
By offloading the speculative decoder to d-Matrix Corsair, we achieved 2-10X interactivity improvements over a homogeneous speculative decoding setup for the same energy efficiency, with the benefit widening as draft lengths increase.
We believe that a disaggregated, heterogeneous architecture is an important foundation as the industry discovers further optimizations. For example, the same technique can be applied to Speculative Speculative Decoding, a recent innovation that parallelizes both drafting and verification across rounds. Our view is that the biggest gains will increasingly come from combining algorithmic advances with specialized hardware. We're excited to pair d-Matrix and other accelerators with the Gimlet stack to further speed up inference stages beyond what is possible on homogeneous infrastructure.
If you'd like to learn more about d-Matrix Corsair, Gimlet, or heterogeneous inference we'd love to hear from you. You can reach us at info@gimletlabs.ai.