Splitting LLM inference across different hardware platforms
- Published on
- Authors

- Name
- Zain Asgar

- Name
- Michelle Nguyen

- Name
- Sachin Katti

- Name
- Natalie Serrino
Splitting LLM inference across different hardware platforms
tl;dr: Separating prefill and decode stages of LLM inference improves token throughput because their resource needs differ. Although most deployments use NVIDIA hardware for both stages, multivendor disaggregation can actually improve efficiency while maintaining SLAs. Based on our models using NVIDIA B200s and Intel Gaudi 3, common workloads can see 1.7X TCO improvement compared to single-vendor disaggregation.
Motivation
The demand for AI inference has risen sharply in 2025. Google went from generating hundreds of trillions per month to 1.3 quadrillion per month in less than a year, and ChatGPT answers 2.5 billion prompts a day. As token volumes explode, so do the costs, and agentic systems exacerbate the problem: a single user request can trigger a variable amount of generated tokens.
Inference providers must balance latency, throughput, and cost efficiency. As Semianalysis noted in the release of InferenceMAX, "TCO per million tokens is the true north star [..] – performance is merely a stepping stone to calculating this metric".
Prefill-decode disaggregation is a common optimization to improve inference cost efficiency. This is a form of pipeline parallelism where the prefill and decode stages are broken up and run on separate GPUs, instead of running on the same GPU together. Splitwise and DistServe, which were seminal papers on the topic, showed 2-7X throughput improvement by using prefill-decode disaggregation.
Most systems still run both stages on NVIDIA GPUs. We decided to evaluate running prefill and decode across different vendors (e.g. NVIDIA for prefill, and Intel for decode). Running across heterogeneous, multivendor hardware can improve cost efficiency and allow for better tradeoffs because it offers more options for the workload.

The prefill and decode stages of LLMs can be run together on the same GPU, or they can be disaggregated across different GPU pools. In this work, we investigate disaggregating these stages across accelerators from different vendors for improved cost per token.
To set the stage, here's a quick review on prefill-decode disaggregation (including prior work), then we will dive into our results.
Refresher on Prefill-Decode Disaggregation
The key observation made by the authors of DistServe and Splitwise is that prefill and decode stages of inference run more efficiently when separated, because they are fundamentally different workloads.
The prefill phase ingests the entire prompt and builds the KV cache, which is highly compute-intensive work. The decode phase generates a single token at a time, and is bottlenecked by memory bandwidth due to frequent KV cache reads.
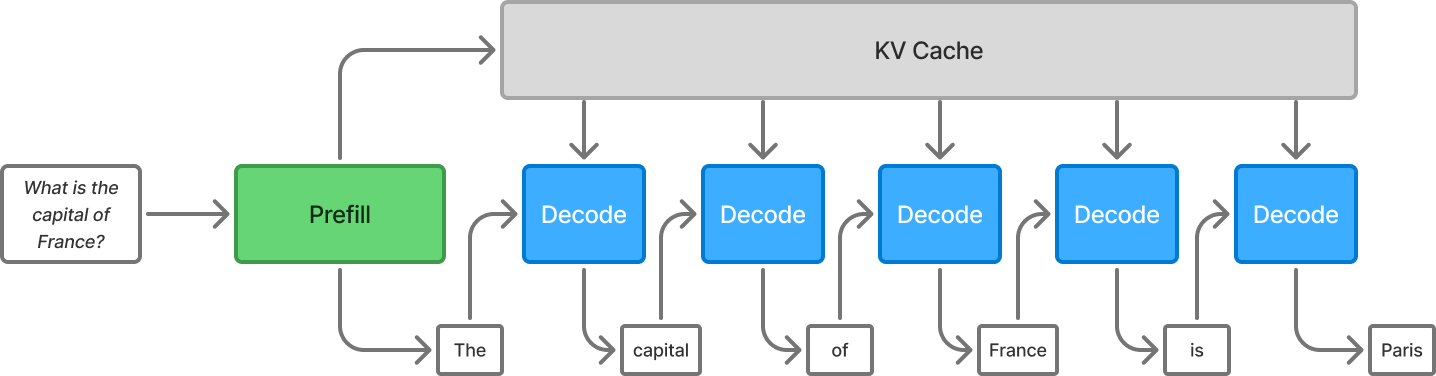
Prefill and decode are the two major stages of LLM inference. In the prefill stage, the input prompt is processed and the first token is produced. Afterwards, the decode phase runs, producing one token at a time, until every token is produced.
When these two stages are run on the same GPU, they interfere with each other. Prefill stages are compute intensive and end up stalling the running decode stages. There is poor overlap in the cached data between the two stages as well, leading to cache contention and inefficient use of memory.
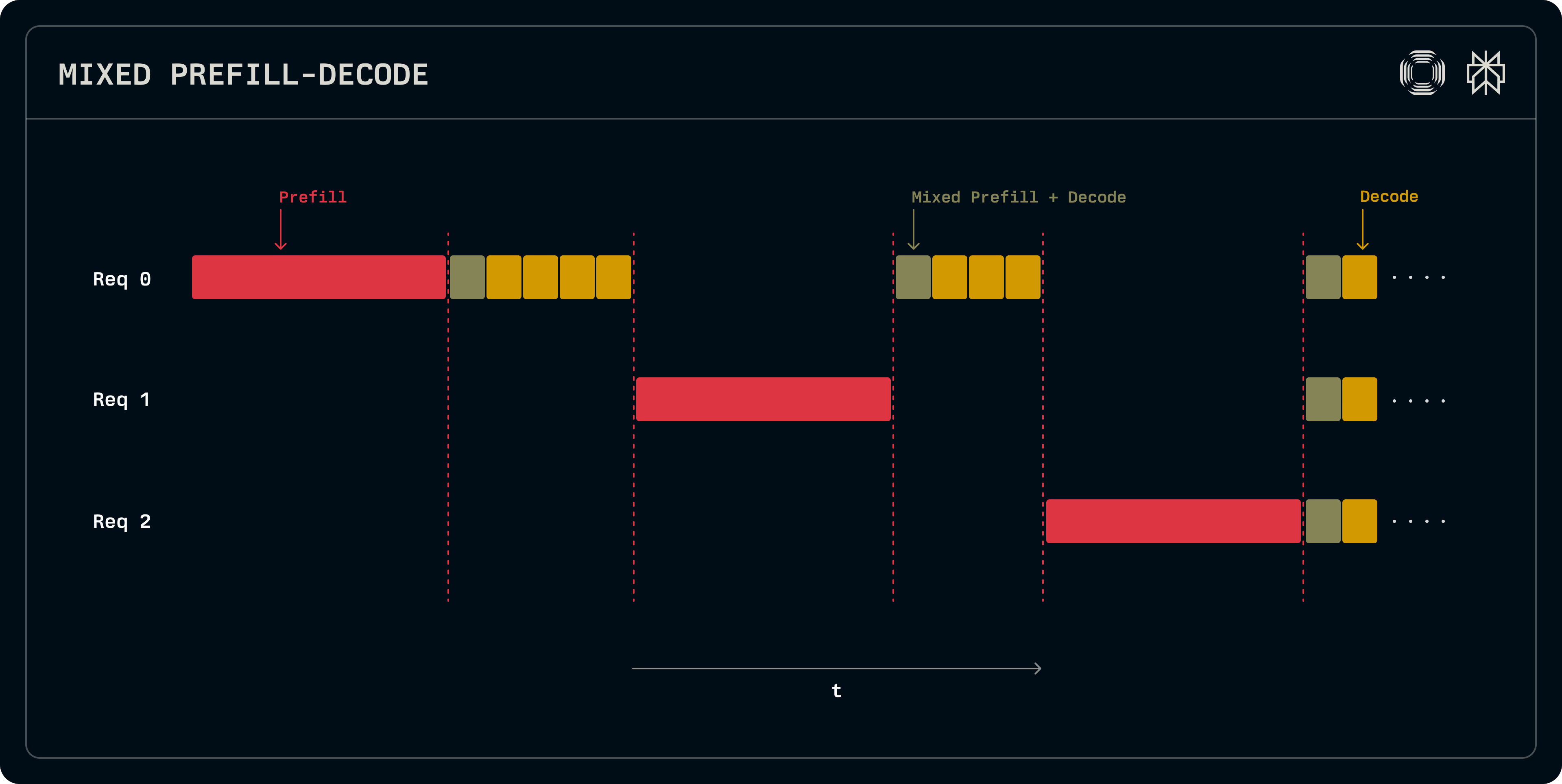
View of a GPU running both prefill and decode stages for multiple requests. With this approach, there is interference between the different stages of the workload. Source: Perplexity.
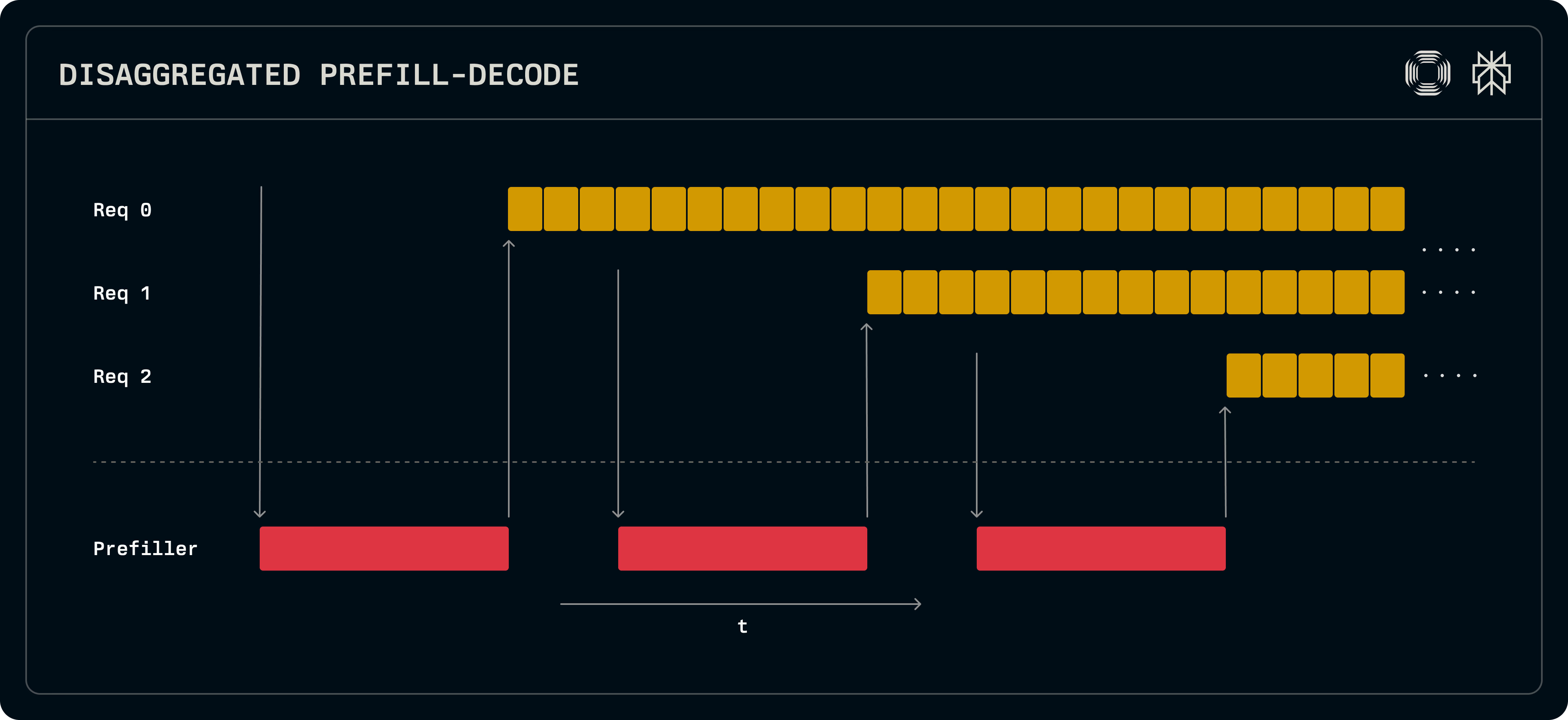
View of two GPUs, one running prefill and the other running decode for multiple requests. This approach improves system throughput. Source: Perplexity.
Running these stages on separate GPUs improves overall system throughput, and therefore also improves cost per token. It may slow down an individual request, which now has to make an extra hop from the prefill GPU to the decode GPU. As a result, the way that people approach prefill-decode disaggregation is to optimize throughput under an acceptable SLA for total request latency.
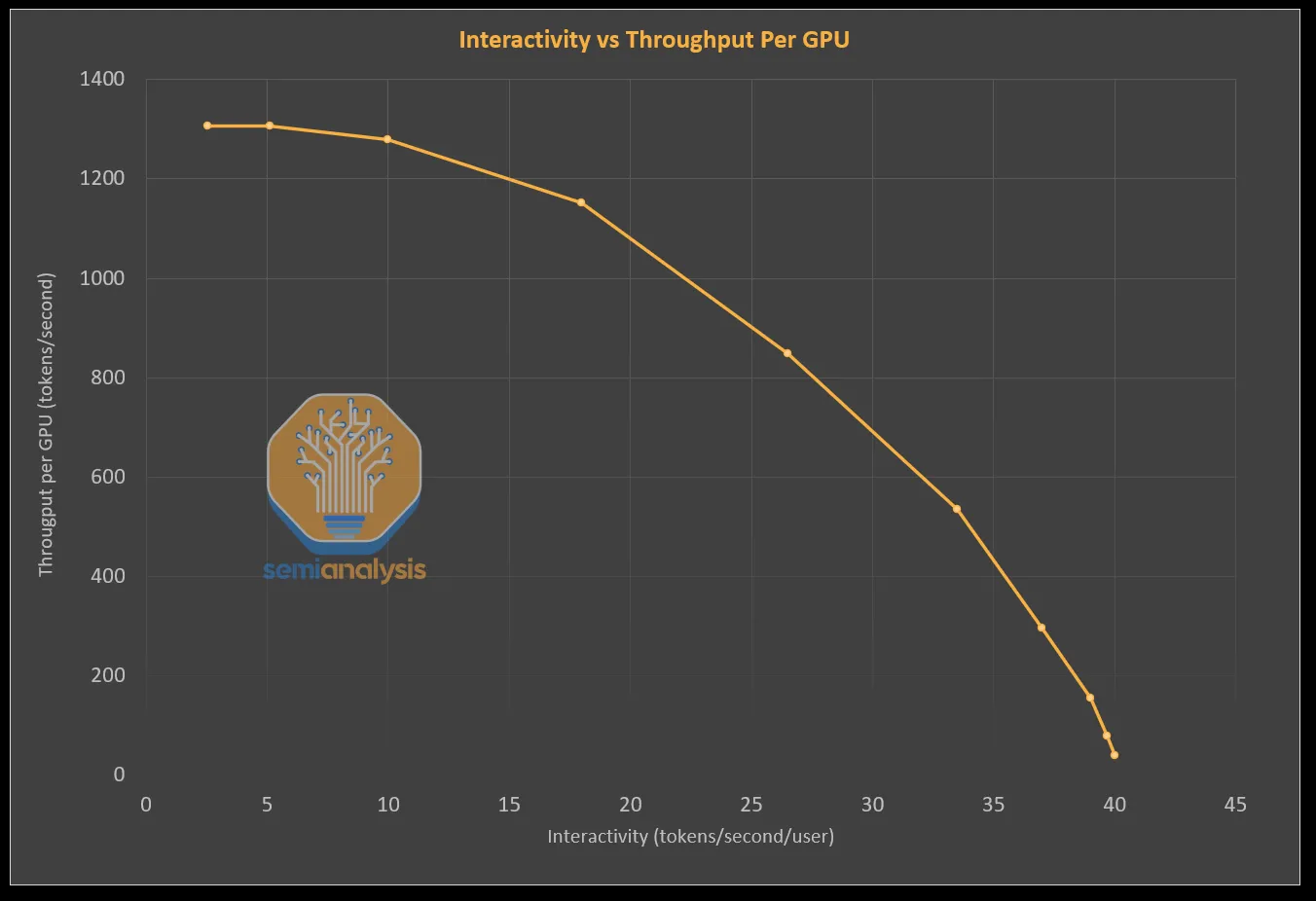
Throughput and interactivity (latency) trade off along a Pareto frontier. Improvements to throughput may increase latency, and vice versa. Large-scale inference workloads set a goal for latency and try to achieve the best throughput under that threshold. Source: Semianalysis.
The authors of Splitwise (Patel et al) achieved 2.35X higher throughput under the same cost budgets. Their work focused on disaggregation across A100 and H100 GPUs. Running both stages on (disaggregated) H100s led to better throughput for a given power budget, and running both stages on A100s led to better throughput for a given cost budget. Running prefill on H100 and decode on A100 performed well under both scenarios.
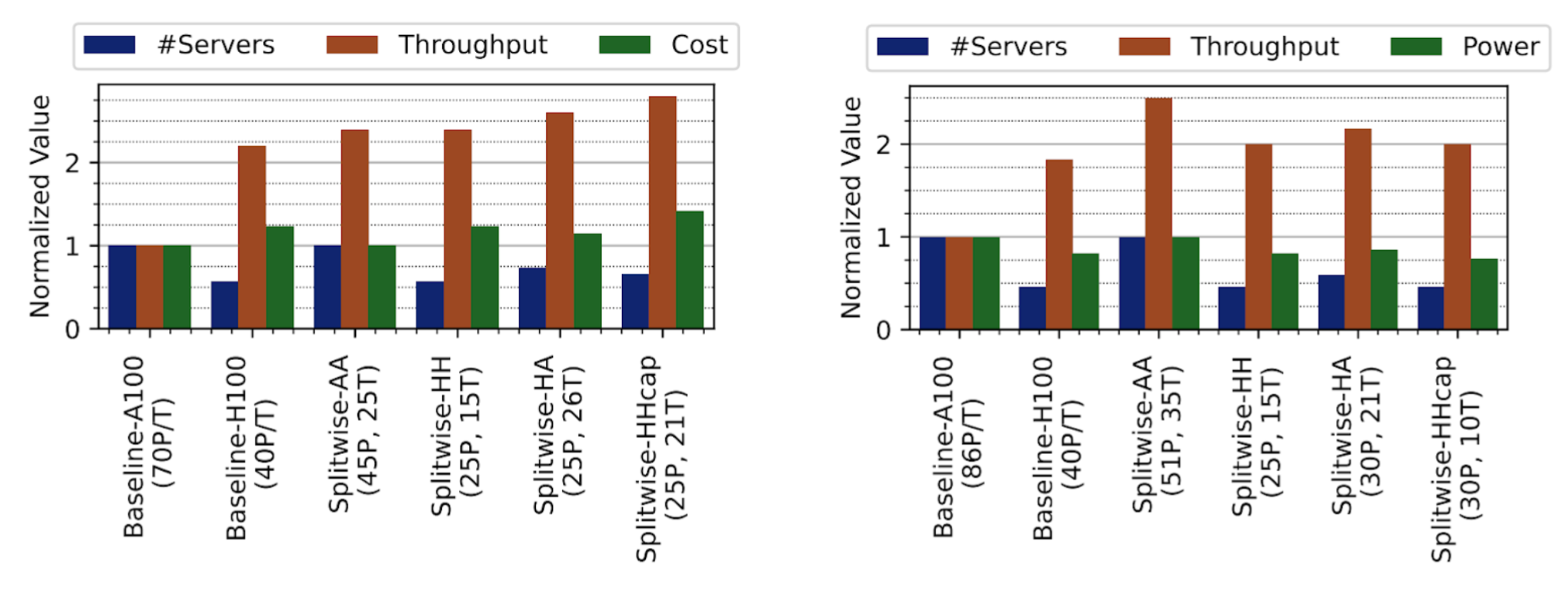
The throughput advantages shown by the Splitwise authors. The left diagram depicts throughput and cost improvements under a fixed power budget. The right diagram depicts throughput and power improvements under a fixed cost budget. Source: Patel et al.
As mentioned earlier, prefill and decode are fundamentally different workloads, with prefill bound by compute resources and decode bound by memory bandwidth. Prefill should map to accelerators (such as GPUs) with high compute capability, whereas decode should map to accelerators with high memory bandwidth.
Exploring multivendor prefill-decode disaggregation strategies
Prefill will excel on accelerators (such as GPUs) with high $/FLOP. Let's assess multiple vendors' accelerators for prefill potential, plotting the cost per FP8 operation, versus the total FP8 capacity of the accelerator. (The reason we want to plot against the total capacity is that there may be a minimum compute we want per device, to avoid unnecessary additional parallelism of the model.)
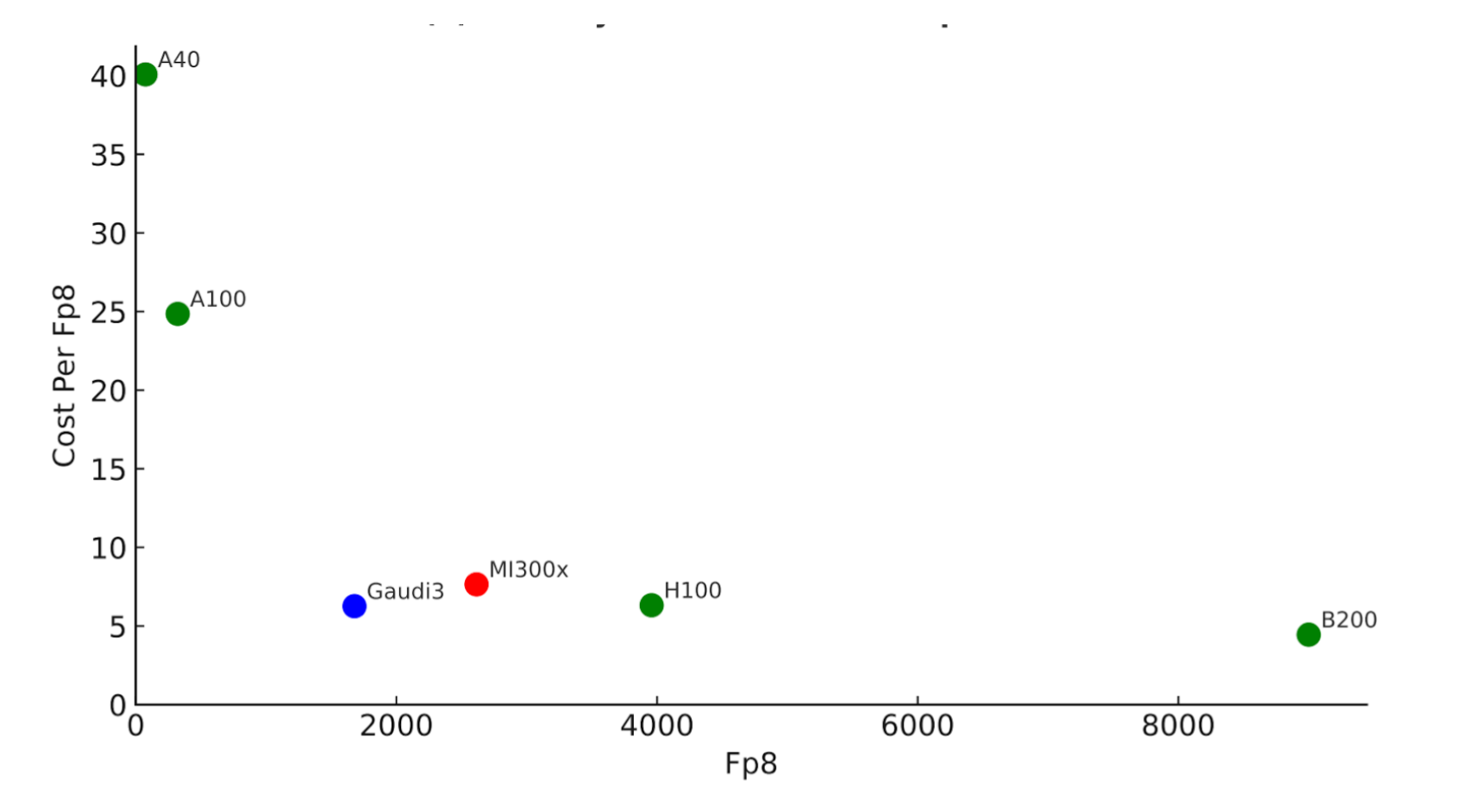
Cost per TFLOP ($) versus total TFLOPs on the accelerator. Based on publicly available accelerator prices, not including power and other elements of TCO. Lower and to the right is the best. Source: Asgar et al.
Lower and to the right is the best, because it has the highest compute and the lowest cost per compute. We can see the NVIDIA B200 is far and away the winner on cost-effective compute capacity here, which means it's likely to be the best prefill node (at least for FP8).
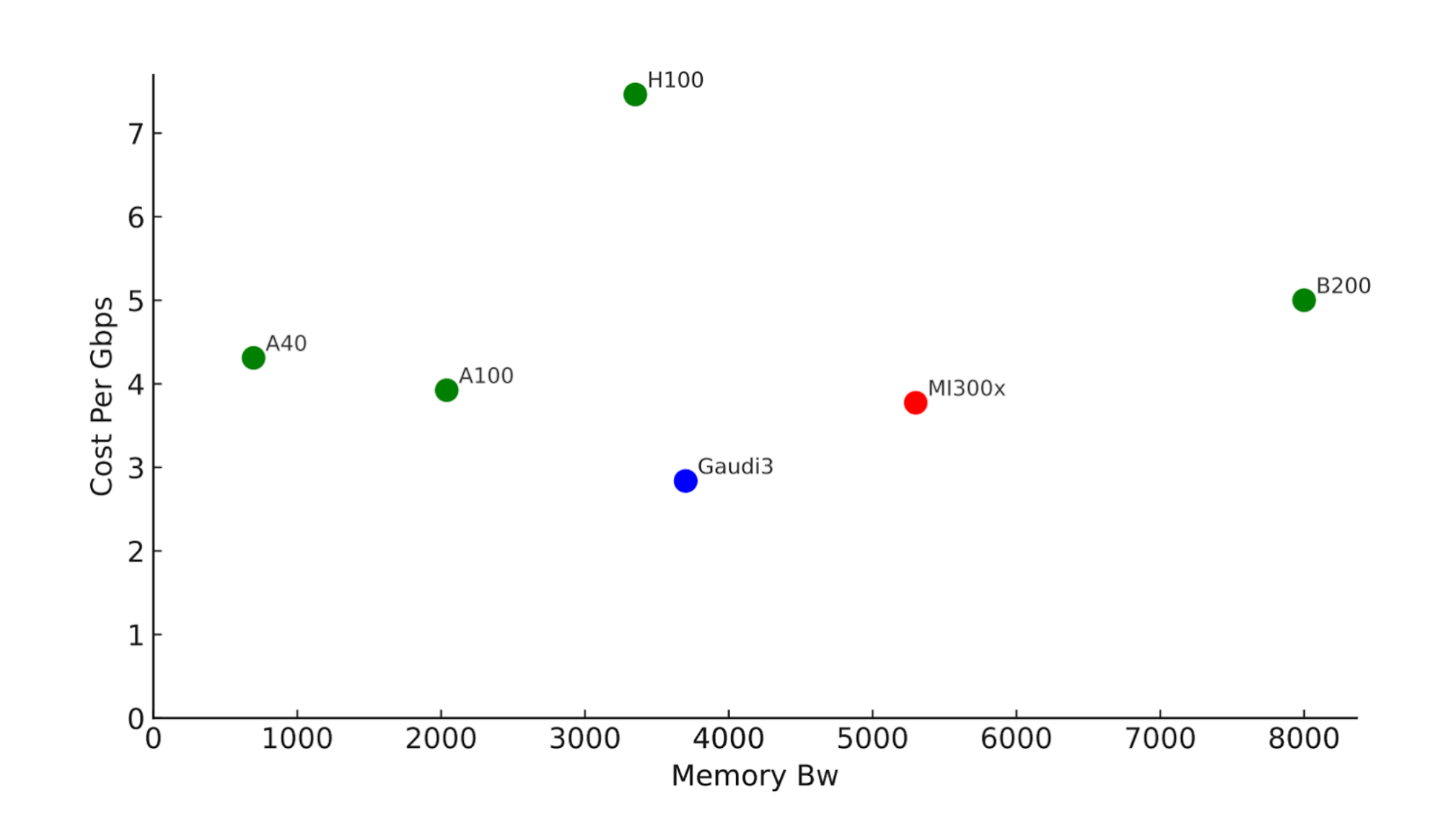
Cost per Gbps versus total memory bandwidth in Gbps. Based on publicly available accelerator prices, not including power and other elements of TCO. Lower and to the right is the best. Source: Asgar et al.
The story for decode is different - we actually see 3 different devices on the Pareto frontier: The Gaudi3, the MI300X, and the B200. Each of these provide cost effective memory bandwidth for a given amount of total memory bandwidth. If 3000-4000 Gbps of total memory bandwidth per device is sufficient, the Gaudi3 will be the best option based on this analysis.
Because the Intel Gaudi 3 offers high memory bandwidth per dollar, we tested it as a decode node and extended our cost model to include power costs.
Assessing NVIDIA prefill / Gaudi 3 decode configurations
In order to assess this configuration, we created fitted roofline models for four LLM workload options. These models can quickly tell us what the performance of the workload should be for different hardware configurations. Our goal was to compare the relative benefits of different disaggregation strategies (since there is already rich prior work establishing the benefits of disaggregation).
In order to feed realistic performance data into the roofline models, we benchmarked H100, B200, and Gaudi 3 accelerators. We tested across different input and output sizes, and set different SLA options. We also included power costs in the estimate for cost. (For more details, see the full preprint.)
The baseline configuration was H100:H100 (disaggregated, both stages running on H100s), since that is a common configuration for LLM deployments today.
For a prefill-heavy workload (4096 input tokens, 512 output tokens), we visualize the 4 top configurations. Compared to the H100:H100 baseline, B200:Gaudi3 offers 3X TCO benefit under both latency-sensitive and throughput-sensitive workloads. It even beats the B200:B200 configurations.
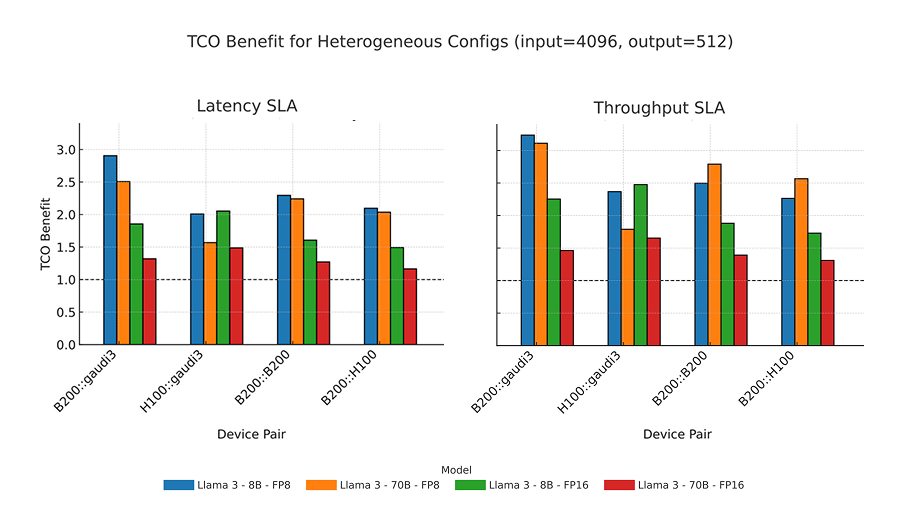
TCO benefit of different disaggregation strategies for prefill-heavy Llama workloads. Source: Asgar et al.
The benefits get even more pronounced for decode-heavy workloads. For workloads with 512 input tokens and 4096 output tokens, such as synthetic data generation, we see even higher TCO advantages of the B200:Gaudi3 configuration:
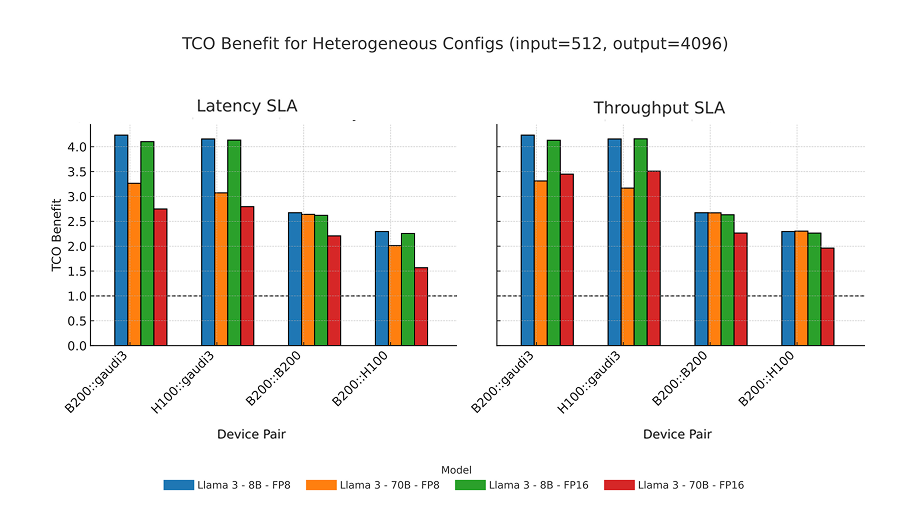
For decode-heavy workloads, the TCO benefit of B200:Gaudi3 rises as high as 4X compared to H100:H100, with the B200:B200 configuration hovering around 2.5X: still solid, but a clear gap. Source: Asgar et al.
What is needed to productionize multivendor disaggregated systems?
There are a few practical considerations to keep in mind about disaggregated architectures. First, the ideal ratio of prefill and decode nodes varies based on the workload. In a real production system, this ratio will vary dynamically. Splitwise solves this problem by reserving some GPUs for either prefill or decode, whatever is needed based on the current application needs.
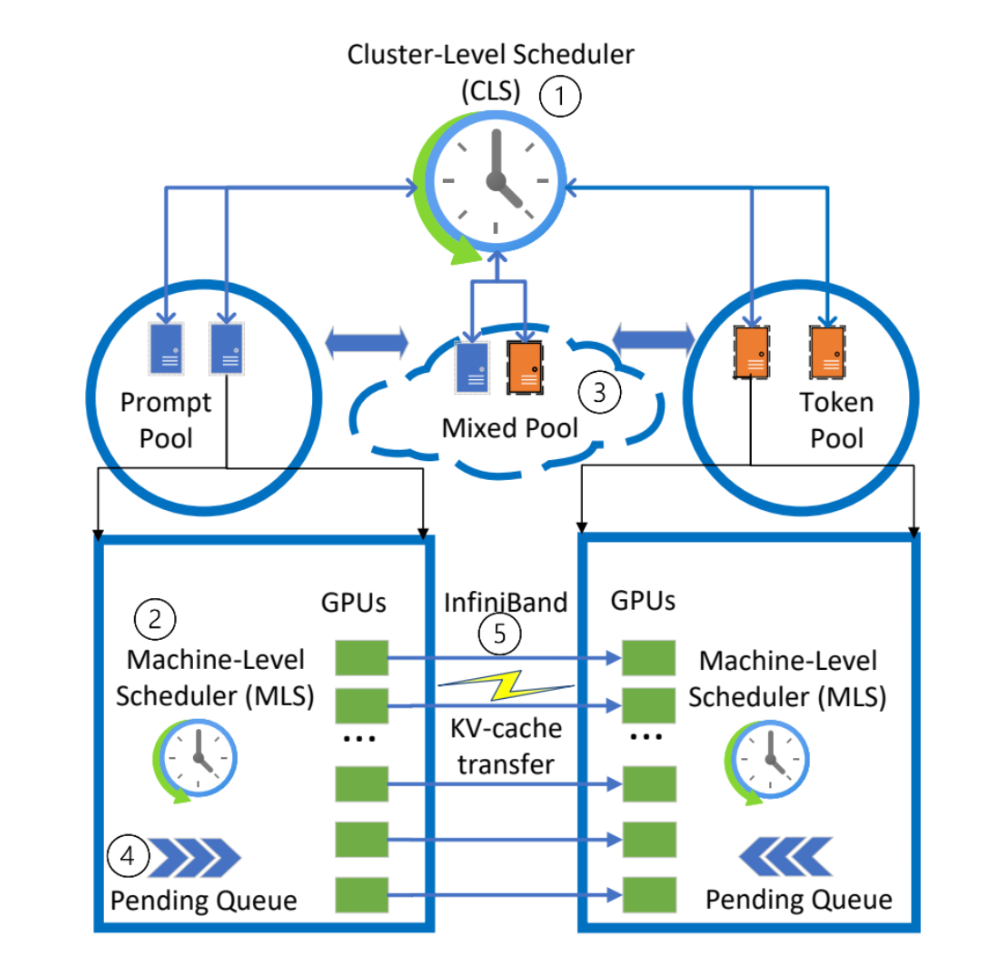
High-level architecture of Splitwise, which maintains 3 pools of GPUs: a prefill pool, and decode pool, and a mixed pool. Source: Patel et al.
Instead of dedicating pools of hardware for specific workload stages, we could adopt a dynamic scheduling model that treats all accelerators as part of a single, shared pool of resources. Tasks such as prefill and decode would be dynamically assigned to the most suitable accelerator based on current availability and workload needs, which improves utilization by avoiding static, per-stage earmarking of resources.
Another improvement would be generalizing disaggregation beyond simply splitting prefill and decode. Agentic systems, which can contain multiple models and non-model stages, can be dynamically partitioned, with each partition being matched to the hardware that is best-suited to that part of the workload. Adopting a heterogeneous pool of accelerators supports better efficiency here, because then these different slices can be run on hardware that best matches their specific needs.
Another aspect to consider is the KV cache transfer, where the KV cache needs to be sent from the prefill node to the decode node. This transfer is required by any disaggregated system, and it only affects the time to the second token (the cache only needs to be transferred once). However, there are ways of pipelining the KV cache transfer to significantly reduce latency, such as the approach proposed by the Splitwise authors. Their pipelined cache transfer shows 5-10ms of latency, which is not large in the context of a query's total latency.
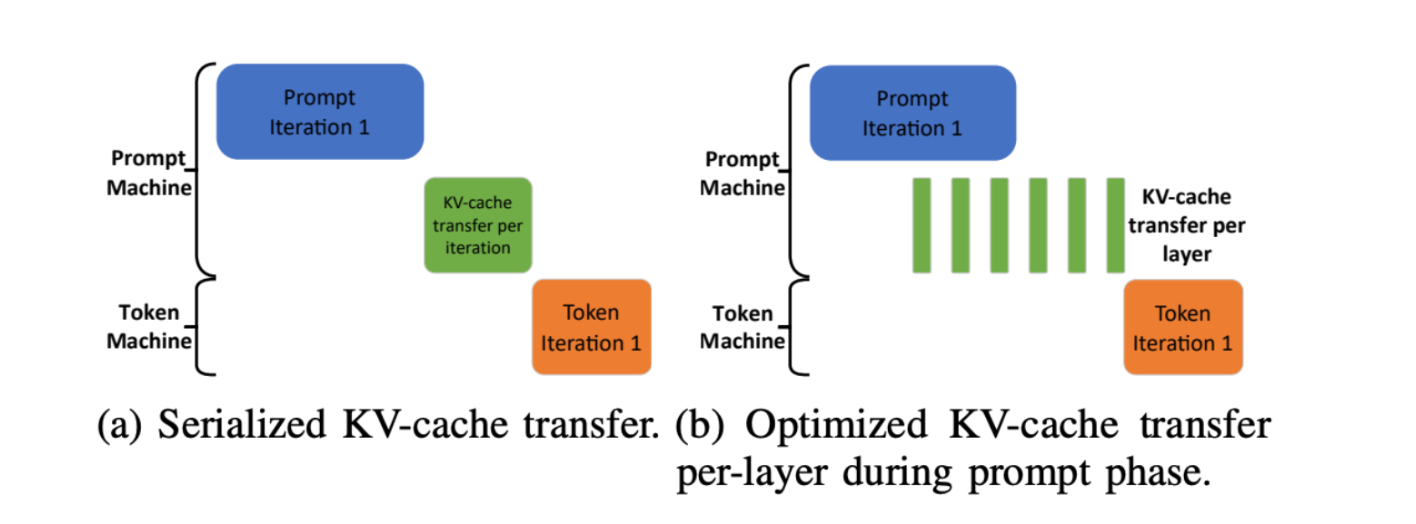
Two modes of KV cache transfer described in Splitwise: serialized, which waits until the prefill phase to complete before sending the KV cache, versus optimized, which sends the KV cache over layer by layer when each layer is ready. Source: Patel et al.
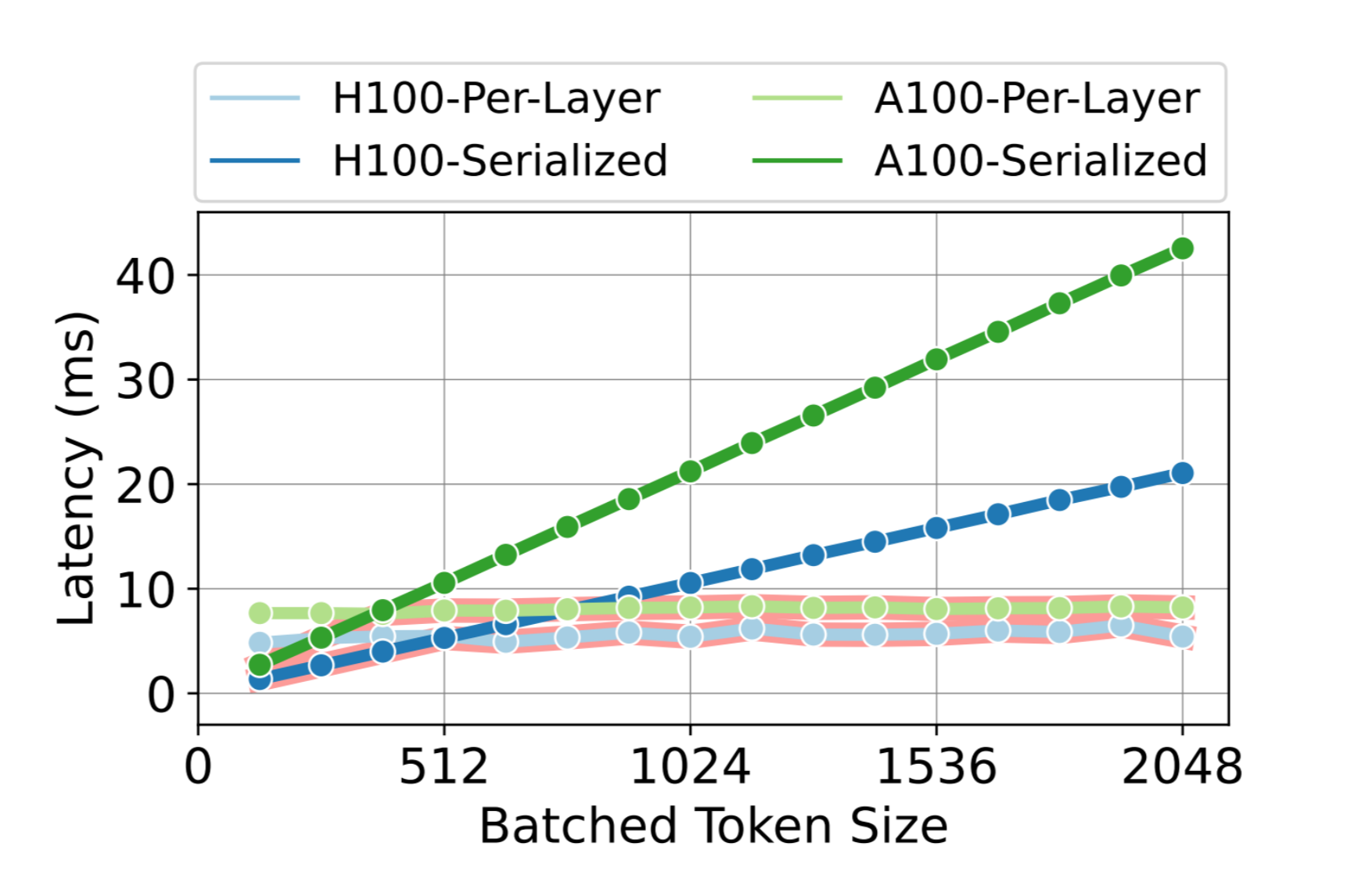
Latency for KV cache transfer modes measured by Splitwise authors. Layer-by-layer transfer provides significantly lower latency overhead as the number of tokens increases. Source: Patel et al.
In multivendor systems, the KV cache format actually varies across different accelerator vendors. This means that the KV cache needs to be translated into the new format sometime during the transfer process. For B200 to Gaudi 3, it involves a few transposes of the cache. We've measured this translation, and it adds negligible latency in practice: on the order of 20-50 microseconds.
Another major aspect to productionizing LLMs across multivendor hardware is the software infrastructure. Today, systems like vLLM and llm-d can deploy LLM inference across different hardware, but platform support is still uneven. As of today, it's challenging to disaggregate the same workload across multivendor accelerator types. If you're interested in that problem, watch this space.
Closing thoughts
Multivendor disaggregation can improve cost efficiency while preserving high end performance in the parts of the workload where it matters most. Considering accelerators from multiple vendors offers us more options on the Pareto frontier for different resources (e.g. memory bandwidth).
NVIDIA's new Rubin CPX further validates the trend toward disaggregated inference across heterogeneous hardware. Rubin is optimized for compute intensity, and will be an excellent addition to the Pareto frontier for stages like prefill.
We are currently running detailed benchmarks across additional vendors such as AMD and across more workloads (e.g. mixture-of-expert models such as DeepSeek). Our roofline models have matched the predicted TCO and performance numbers shown above, and we'll share the expanded benchmarks and results shortly.
Interested in learning more about how to run inference across heterogeneous hardware platforms? Feel free to reach out at hello@gimletlabs.ai.