Benchmarking AI-generated CUDA kernels on an H100
- Published on
- Authors

- Name
- Taras Sereda

- Name
- Natalie Serrino

- Name
- Zain Asgar

- Name
- Burak Bartan
Benchmarking AI-generated CUDA kernels on an H100
tl;dr: We extended our kernel generation research to CUDA, and benchmarked results on an H100. The generated kernels achieve a ~1.8X speedup on KernelBench problems over the baseline PyTorch (including torch.compile).
Introduction
Autonomous kernel generation by AI models is an active research area, because it offers the chance to speed up AI workloads without low-level kernel expertise. This approach could potentially allow ML researchers to stay in pure PyTorch, while gaining the performance of optimized kernels. It can also allow for more immediate optimized support for new models across different hardware platforms.
In an earlier post, we shared benchmark results for Metal kernels generated for Apple devices. We found in that work that an agentic swarm (where multiple agents work together to find the best implementation) provides significantly better performance than a single agent.
We wanted to extend this work to generating CUDA kernels, since NVIDIA devices are widely used for AI workloads. Going into the investigation, it wasn’t clear whether the agentic swarm would be better at improving performance for Metal or CUDA kernels. On one hand, there are far more examples of CUDA kernels online for the agents to learn from. On the other hand, more time has been spent optimizing PyTorch for NVIDIA hardware than for Apple devices.
It turns out that the results are comparable, with AI-generated CUDA kernels performing slightly better than AI-generated Metal kernels. Let’s dive into the results, but first cover how these results were collected and compared against the baseline.
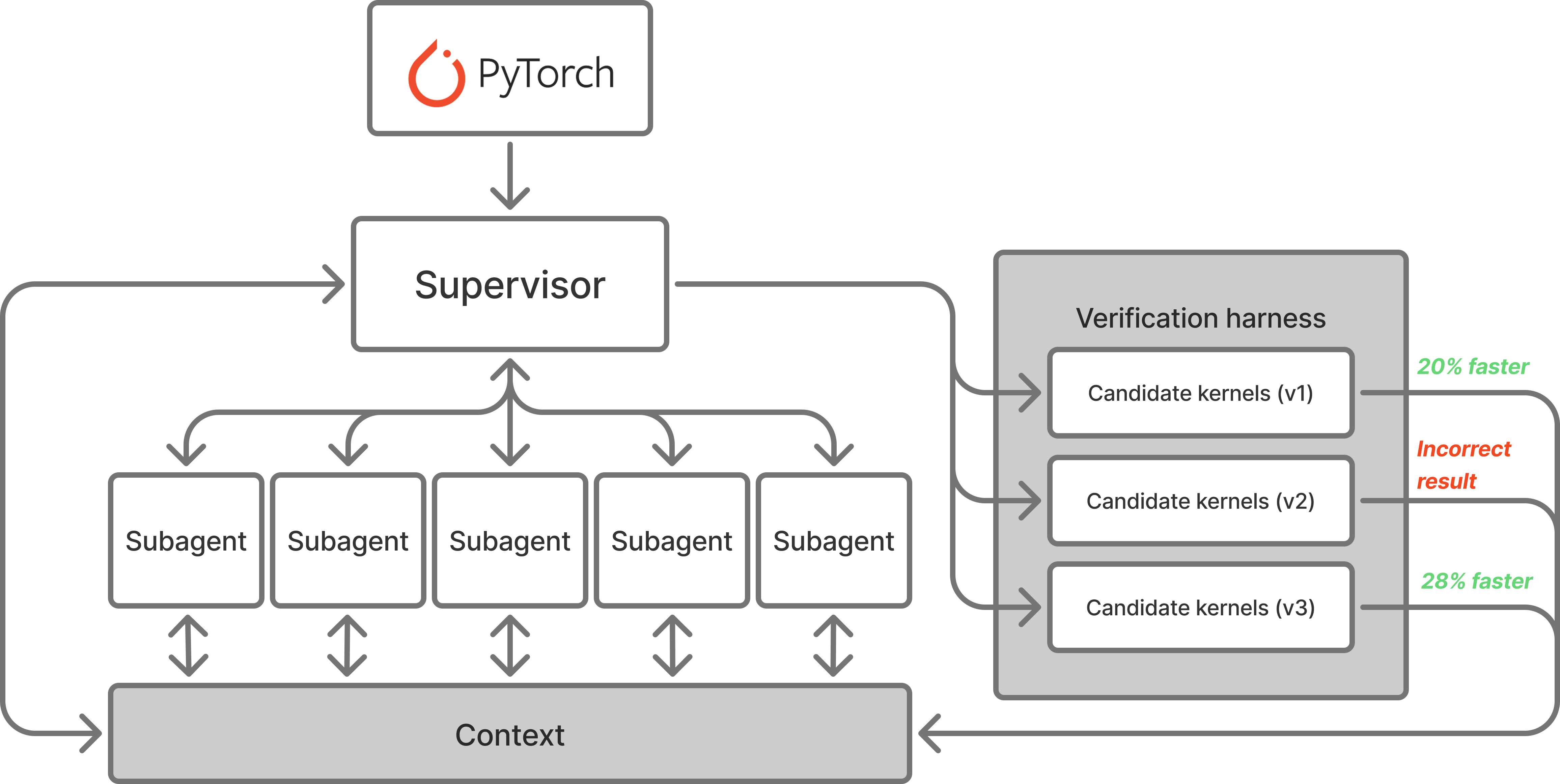
System architecture for our agentic swarm. It takes as input a PyTorch implementation as the prompt, and multiple work to identify the best solution. Candidate kernels are verified for numerical equivalence and performance against corresponding reference implementations.
Benchmarking methodology
Benchmarking kernel performance has a lot of subtle pitfalls, so we are sharing the benchmark code used to assess kernel performance. It’s important when running PyTorch benchmarks to ensure that warmups are performed, caches are cleared, and synchronization is conducted.
1import argparse
2import time
3from dataclasses import dataclass, field
4from pathlib import Path
5
6import polars as pl
7import torch
8import torch.nn as nn
9import torch.utils.benchmark as benchmark
10
11if torch.cuda.is_available():
12 import triton
13
14 TRITON_AVAILABLE = True
15else:
16 TRITON_AVAILABLE = False
17
18
19def set_seed(seed: int):
20 torch.manual_seed(seed)
21 torch.cuda.manual_seed(seed)
22 torch.mps.manual_seed(seed)
23
24
25@dataclass(repr=False)
26class Perf:
27 name: str
28 ellapsed_time: list[float]
29 n_trials: int
30
31 time_mean: float = field(init=False)
32 time_median: float = field(init=False)
33 time_std: float = field(init=False)
34 time_min: float = field(init=False)
35 time_max: float = field(init=False)
36
37 def __post_init__(self):
38 assert len(self.ellapsed_time) == self.n_trials
39 time_th = torch.Tensor(self.ellapsed_time)
40 self.time_mean = time_th.mean()
41 self.time_median = time_th.median()
42 self.time_std = time_th.std()
43 self.time_min = time_th.min()
44 self.time_max = time_th.max()
45
46 def __repr__(self) -> str:
47 return (
48 f"Perf: time in ms\n"
49 f"{'n_trials':<10} = {self.n_trials}\n"
50 f"{'mean':<10} = {self.time_mean:.4f}\n"
51 f"{'median':<10} = {self.time_median:.4f}\n"
52 f"{'std':<10} = {self.time_std:.4f}\n"
53 f"{'min':<10} = {self.time_min:.4f}\n"
54 f"{'max':<10} = {self.time_max:.4f}\n"
55 )
56
57 def stat_dict(self) -> dict:
58 return {
59 "name": self.name,
60 "n_trials": self.n_trials,
61 "mean": self.time_mean,
62 "median": self.time_median,
63 "std": self.time_std,
64 "min": self.time_min,
65 "max": self.time_max,
66 }
67
68
69@dataclass(repr=False)
70class ComparePerf:
71 perf_results: list[Perf]
72
73 def __repr__(self) -> str:
74 perf_df = pl.from_dicts(perf.stat_dict() for perf in self.perf_results)
75 return f"{perf_df}"
76
77
78@dataclass(repr=False)
79class CompareMeasurement:
80 perf_results: list[benchmark.Measurement]
81
82 def __repr__(self) -> str:
83 perf_df = pl.from_dicts(
84 {
85 "name": perf.task_spec.summarize().replace("\n", " "),
86 "n_trials": perf.number_per_run,
87 "median": perf.median * 1e3,
88 "mean": perf.mean * 1e3,
89 }
90 for perf in self.perf_results
91 )
92 return f"{perf_df}"
93
94
95def get_empty_cache_for_benchmark(device):
96 cache_size = 256 * 1024 * 1024
97 return torch.empty(int(cache_size // 4), dtype=torch.int, device=device)
98
99
100def clear_cache(cache):
101 cache.zero_()
102
103
104def compare_perf(perf_results: list[Perf | benchmark.Measurement]):
105 if isinstance(perf_results[0], Perf):
106 return ComparePerf(perf_results)
107 elif isinstance(perf_results[0], benchmark.Measurement):
108 # proceed with benchmark.Compare
109 return CompareMeasurement(perf_results)
110
111
112def load_reference(ref_src: str, ctx):
113 try:
114 compile(ref_src, "<string>", "exec")
115 except SyntaxError as e:
116 raise e
117
118 try:
119 exec(ref_src, ctx)
120 except Exception as e:
121 raise RuntimeError(f"Error in executing src model. {e}") from e
122
123 # these should be defined in the original model code and present in the context
124 get_init_inputs_fn = ctx.get("get_init_inputs")
125 get_inputs_fn = ctx.get("get_inputs")
126 Model = ctx.get("Model")
127 return Model, get_init_inputs_fn, get_inputs_fn
128
129
130def load_target(tgt_src: str, ctx: dict, build_dir: str = None) -> nn.Module:
131 if build_dir:
132 tgt_src = (
133 f"""
134import os
135os.environ['TORCH_EXTENSIONS_DIR'] = '{build_dir}'
136"""
137 ) + tgt_src
138 local_ctx = {}
139 try:
140 compile(tgt_src, "<string>", "exec")
141 except SyntaxError as e:
142 raise e
143 try:
144 exec(tgt_src, local_ctx)
145 except Exception as e:
146 raise RuntimeError(f"Error in executing tgt model. {e}") from e
147
148 ModelNew = local_ctx.get("ModelNew")
149 # update execution context with ModelNew only
150 ctx["ModelNew"] = ModelNew
151 return ModelNew
152
153
154@torch.inference_mode()
155def benchmark_triton(model, inputs, num_trials=100, num_warmup=3) -> Perf:
156 def func():
157 model(*inputs)
158
159 bench_res = triton.testing.do_bench(
160 func,
161 warmup=num_warmup,
162 rep=num_trials,
163 return_mode="all",
164 )
165 perf = Perf(model.__class__.__name__, bench_res, len(bench_res))
166 return perf
167
168
169@torch.inference_mode()
170def benchmark_event(model, inputs, num_trials=100, num_warmup=3) -> Perf:
171 device = inputs[0].device
172 # warm up
173 for _ in range(num_warmup):
174 _ = model(*inputs)
175 torch.accelerator.synchronize()
176
177 cache = get_empty_cache_for_benchmark(device)
178
179 start_event = [
180 torch.Event(device=device, enable_timing=True) for _ in range(num_trials)
181 ]
182 end_event = [
183 torch.Event(device=device, enable_timing=True) for _ in range(num_trials)
184 ]
185 for i in range(num_trials):
186 clear_cache(cache)
187 start_event[i].record()
188 _ = model(*inputs)
189 end_event[i].record()
190
191 torch.accelerator.synchronize()
192 exec_time = [start_event[i].elapsed_time(end_event[i]) for i in range(num_trials)]
193 perf = Perf(model.__class__.__name__, exec_time, num_trials)
194 return perf
195
196
197@torch.inference_mode()
198def benchmark_simple(model, inputs, num_trials=100, num_warmup=3) -> Perf:
199 # warm up
200 for _ in range(num_warmup):
201 _ = model(*inputs)
202 torch.accelerator.synchronize()
203
204 exec_time = []
205 for _ in range(num_trials):
206 start_time = time.perf_counter()
207 _ = model(*inputs)
208 torch.accelerator.synchronize()
209 end_time = time.perf_counter()
210 exec_time.append((end_time - start_time) * 1e3)
211 perf = Perf(model.__class__.__name__, exec_time, num_trials)
212 return perf
213
214
215@torch.inference_mode()
216def check_correctness(model_src, model_tgt, inputs):
217 src_out = model_src(*inputs)
218 tgt_out = model_tgt(*inputs)
219
220 is_close = torch.allclose(src_out, tgt_out, atol=1e-02, rtol=1e-02)
221
222 print(f"Results match: {is_close}")
223 if not is_close:
224 abs_diff = torch.abs(src_out - tgt_out)
225 max_diff = torch.max(abs_diff).item()
226 avg_diff = torch.mean(abs_diff).item()
227 print(f"max abs diff: {max_diff:.8f}")
228 print(f"mean abs diff: {avg_diff:.8f}")
229
230 return is_close
231
232
233def benchmark_problem(ref_src, tgt_src, device, num_trials, num_warmup):
234 set_seed(args.seed)
235
236 ctx = {}
237 Model, get_init_inputs_fn, get_inputs_fn = load_reference(ref_src, ctx)
238 ModelNew = load_target(tgt_src, ctx)
239
240 init_data = [
241 itm.to(device=args.device) if isinstance(itm, torch.Tensor) else itm
242 for itm in get_init_inputs_fn()
243 ]
244 inputs = [
245 itm.to(device=args.device) if isinstance(itm, torch.Tensor) else itm
246 for itm in get_inputs_fn()
247 ]
248
249 set_seed(args.seed)
250 model_tgt = ModelNew(*init_data)
251
252 set_seed(args.seed)
253 model_src = Model(*init_data)
254
255 model_tgt.to(args.device)
256 model_src.to(args.device)
257 torch.accelerator.synchronize()
258
259 bench_funcs = [benchmark_simple, benchmark_event]
260 if TRITON_AVAILABLE:
261 bench_funcs.append(benchmark_triton)
262
263 perfs = {}
264 for bench_fn in bench_funcs:
265 perfs[bench_fn] = {}
266 for model in [model_src, model_tgt]:
267 perf_result = bench_fn(model, inputs, args.num_trials, args.num_warmup)
268 perfs[bench_fn][model.__class__.__name__] = perf_result
269
270 comparison = compare_perf(list(perfs[bench_fn].values()))
271 print(bench_fn.__name__, comparison)
272
273 check_correctness(model_src, model_tgt, inputs)
274 return perfs
275
276
277def main(args):
278 # benchmark all problems in the target directory
279 if args.tgt_dir:
280 from kernel_gen.dataset import construct_kernelbench_dataset
281 from kernel_gen.utils.data import fetch_ref_arch_from_problem_id
282 from kernel_gen.utils.file import get_level_problem_id_from_gen_arc_path
283
284 args.tgt_dir = Path(args.tgt_dir)
285 for tgt_problem_path in args.tgt_dir.glob("**/*kernel.py"):
286 lvl_id, prob_id = get_level_problem_id_from_gen_arc_path(tgt_problem_path)
287 dataset = construct_kernelbench_dataset(lvl_id)
288 ref_src = fetch_ref_arch_from_problem_id(dataset, prob_id, "local")
289
290 with open(tgt_problem_path, "r") as f:
291 tgt_src = f.read()
292
293 benchmark_problem(
294 ref_src,
295 tgt_src,
296 args.device,
297 args.num_trials,
298 args.num_warmup,
299 )
300 # benchmark a single problem
301 else:
302 with open(args.ref_problem, "r") as f:
303 ref_src = f.read()
304
305 with open(args.tgt_problem, "r") as f:
306 tgt_src = f.read()
307
308 benchmark_problem(
309 ref_src,
310 tgt_src,
311 args.device,
312 args.num_trials,
313 args.num_warmup,
314 )
315
316
317if __name__ == "__main__":
318 # torch.set_num_threads(1)
319 parser = argparse.ArgumentParser()
320 parser.add_argument("--ref-problem", type=str)
321 parser.add_argument("--tgt-problem", type=str)
322 parser.add_argument("--tgt-dir", type=str, default=None)
323 parser.add_argument("--num-trials", type=int, default=100)
324 parser.add_argument("--num-warmup", type=int, default=3)
325 parser.add_argument("--device")
326 parser.add_argument("--seed", type=int, default=42)
327
328 args = parser.parse_args()
329 args.device = torch.device(args.device)
330 main(args)For this post, we benchmarked the CUDA kernel generation on an H100, and will follow with results on additional NVIDIA GPUs.
For the input PyTorch models, we used the original KernelBench Levels 1-31. For those who are unfamiliar, KernelBench is a popular benchmark of neural network operators, building blocks and end to end architectures of varying complexity implemented as PyTorch modules. Level 1 problems are the least complex, and Level 3 problems are the most complex. We omitted a few cases from the original set of problems, because the agents found (technically correct) shortcuts compared to the original implementations that provided disproportionate speedups.
In this work, we always use 1X as the baseline speedup (no speedup), because our system will automatically fall back to the baseline implementation when the generated kernels are slower. Additionally, as before, we use geometric mean to compute the average speedup2.
What about torch.compile?
torch.compile is a great PyTorch feature that automatically speeds up PyTorch code using JIT compilation, kernel fusion, and graph analysis. It’s widely adopted, and it provides great support for CUDA (Metal support is in progress).
We want to compare generated kernels against a realistic scenario, not an artificially low bar. Actual practitioners who care about improving model speed would likely at least try torch.compile. As a result, we compare our generated kernels against torch.compile baselines3.
Sometimes eager mode is actually faster in the version of KernelBench we tried. This surprised us, and we welcome any feedback on our benchmarking methodology. This is more common for the simpler modules (e.g. Level 1) - which makes sense because complex modules are more likely to benefit from kernel fusion. Additionally, for smaller runtimes, the overhead of torch.compile may dominate. As a result, we compare our generated kernels to whichever baseline is the higher bar for each problem. (We expect that the win rate of torch.compile increases for the later version of KernelBench, which we will switch to in future posts.)
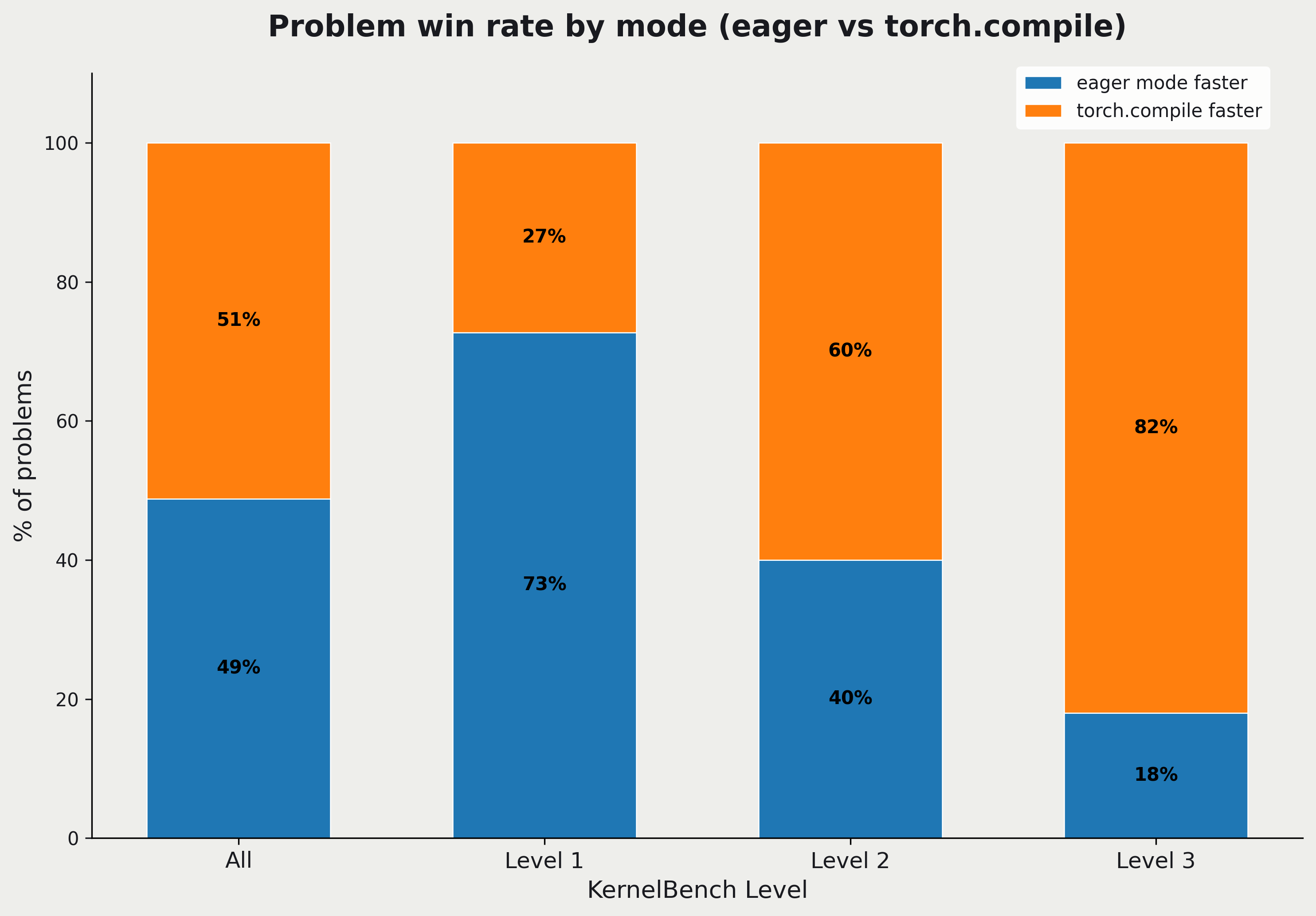
Chart showing whether torch.compile or eager mode is faster in our measurements on an H100, broken down by KernelBench level. We can see that torch.compile starts gaining an advantage as the problems become more complex.
Show me the results!
We see similar results to the generated Metal kernels: about 1.8X speedup when compared to the better-performing PyTorch mode (eager mode or torch.compile).
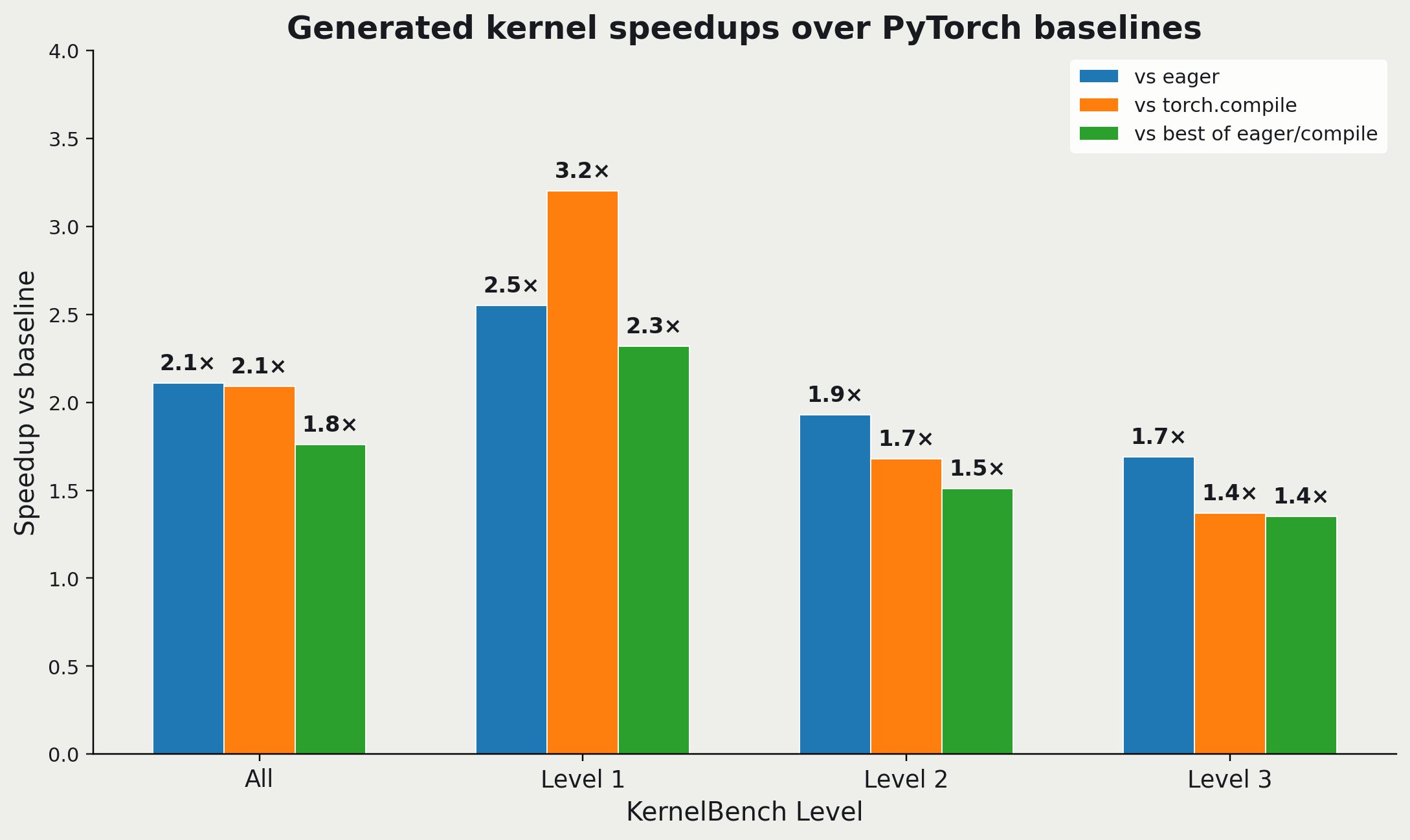
Results for the AI-generated CUDA kernels on the H100. We can see that the average speedup is about 1.8X when compared to the better-performing PyTorch mode (eager vs torch.compile).
Focusing on the green bars, which provide the most rigorous comparison: We can see that the results are strongest for the less complex PyTorch modules (2.3X), and remain strong but drop as we get to Level 3 (1.4X). This tells us that the agentic swarm likely has room for improvement, since more complex modules should actually have more opportunities for performance optimization. (Individual ops are already well-optimized in PyTorch).
Kernel fusion (where multiple kernels are rewritten as a single kernel) is a key part of improving performance, and most of the AI generated kernels make use of fusion. However, other techniques beyond fusion show up as well. For example, the agentic swarm generated fused kernels for Level 2 Problem 94 (Gemm_BiasAdd_Hardtanh_Mish_GroupNorm), but it also added a few other optimizations. There is a hardware-specific optimization of enabling tensor cores (which are specific to NVIDIA). There was also an algorithmic optimization, where different kernel implementations are selected based on the group size in the GroupNorm layer.
Gemm_BiasAdd_Hardtanh_Mish_GroupNorm (Level 2 Problem 94)
1import torch
2import torch.nn as nn
3
4class Model(nn.Module):
5 """
6 A model that performs a GEMM, BiasAdd, Hardtanh, Mish, and GroupNorm operations in sequence.
7 """
8 def __init__(self, in_features, out_features, bias_shape, num_groups):
9 super(Model, self).__init__()
10 self.gemm = nn.Linear(in_features, out_features)
11 self.bias = nn.Parameter(torch.randn(bias_shape))
12 self.hardtanh = nn.Hardtanh()
13 self.mish = nn.Mish()
14 self.groupnorm = nn.GroupNorm(num_groups=num_groups, num_channels=out_features)
15
16 def forward(self, x):
17 """
18 Args:
19 x (torch.Tensor): Input tensor of shape (batch_size, in_features).
20 Returns:
21 torch.Tensor: Output tensor of shape (batch_size, out_features).
22 """
23 x = self.gemm(x)
24 x = x + self.bias
25 x = self.hardtanh(x)
26 x = self.mish(x)
27 x = self.groupnorm(x)
28 return x
29
30
31batch_size = 128
32in_features = 512
33out_features = 1024
34bias_shape = (out_features,)
35num_groups = 32
36
37def get_inputs():
38 return [torch.randn(batch_size, in_features)]
39
40def get_init_inputs():
41 return [in_features, out_features, bias_shape, num_groups]1import torch
2import torch.nn as nn
3import torch.nn.functional as F
4from torch.utils.cpp_extension import load_inline
5
6cuda_src = r"""
7#include <torch/extension.h>
8#include <cuda.h>
9#include <cuda_runtime.h>
10#include <cmath>
11
12// Simple checks
13#define CHECK_CUDA(x) TORCH_CHECK(x.is_cuda(), #x " must be a CUDA tensor")
14#define CHECK_CONTIGUOUS(x) TORCH_CHECK(x.is_contiguous(), #x " must be contiguous")
15#define CHECK_FLOAT32(x) TORCH_CHECK(x.scalar_type() == at::ScalarType::Float, #x " must be float32")
16#define CHECK_INPUT_F32(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x); CHECK_FLOAT32(x)
17
18#ifndef WARP_SIZE
19#define WARP_SIZE 32
20#endif
21
22__device__ __forceinline__ float hardtanhf_fast(float x, float min_v, float max_v) {
23 return fminf(fmaxf(x, min_v), max_v);
24}
25
26// Numerically-stable softplus: log1p(exp(-|x|)) + max(x, 0)
27__device__ __forceinline__ float softplusf_stable_fast(float x) {
28 float ax = fabsf(x);
29 return log1pf(__expf(-ax)) + fmaxf(x, 0.0f);
30}
31
32__device__ __forceinline__ float mishf_fast(float x) {
33 float sp = softplusf_stable_fast(x);
34 return x * tanhf(sp);
35}
36
37// Warp reduce sum using shuffles
38__device__ __forceinline__ float warp_sum(float v) {
39 unsigned mask = 0xffffffffu;
40 v += __shfl_down_sync(mask, v, 16);
41 v += __shfl_down_sync(mask, v, 8);
42 v += __shfl_down_sync(mask, v, 4);
43 v += __shfl_down_sync(mask, v, 2);
44 v += __shfl_down_sync(mask, v, 1);
45 return v;
46}
47
48static inline int next_pow2_int(int v) {
49 if (v <= 1) return 1;
50 v--;
51 v |= v >> 1;
52 v |= v >> 2;
53 v |= v >> 4;
54 v |= v >> 8;
55 v |= v >> 16;
56 return v + 1;
57}
58
59// Fast path: One warp handles one (sample, group). No shared memory, keep values in registers.
60// Requires: group_size <= 32
61__global__ void fused_bias_act_gn_warp_kernel(
62 const float* __restrict__ z, // [N, C]
63 const float* __restrict__ b1, // [C] linear bias (may be nullptr)
64 const float* __restrict__ b2, // [C] extra bias (may be nullptr)
65 const float* __restrict__ gamma, // [C]
66 const float* __restrict__ beta, // [C]
67 float* __restrict__ y, // [N, C]
68 int N, int C, int G,
69 float ht_min, float ht_max, float eps
70){
71 const int n = blockIdx.y;
72 const int g = blockIdx.x;
73 const int lane = threadIdx.x & 31;
74
75 const int group_size = C / G;
76 if (group_size > WARP_SIZE) return;
77
78 const int c0 = g * group_size;
79 const int base = n * C + c0;
80
81 float m = 0.0f;
82 if (lane < group_size) {
83 const int c = c0 + lane;
84 float v = z[base + lane];
85 if (b1) v += b1[c];
86 if (b2) v += b2[c];
87 v = hardtanhf_fast(v, ht_min, ht_max);
88 m = mishf_fast(v);
89 }
90
91 float sum = warp_sum(m);
92 float sq = warp_sum(m * m);
93
94 unsigned mask = 0xffffffffu;
95 float sum_all = __shfl_sync(mask, sum, 0);
96 float sq_all = __shfl_sync(mask, sq, 0);
97
98 float mean = sum_all / (float)group_size;
99 float var = sq_all / (float)group_size - mean * mean;
100 float rstd = rsqrtf(var + eps);
101
102 if (lane < group_size) {
103 const int c = c0 + lane;
104 float gmul = gamma ? gamma[c] : 1.0f;
105 float gbias = beta ? beta[c] : 0.0f;
106 float gn = (m - mean) * rstd;
107 y[base + lane] = gn * gmul + gbias;
108 }
109}
110
111// General kernel: shared mem reduction, any group size.
112__global__ void fused_bias_act_gn_block_kernel(
113 const float* __restrict__ z, // [N, C]
114 const float* __restrict__ b1, // [C]
115 const float* __restrict__ b2, // [C]
116 const float* __restrict__ gamma, // [C]
117 const float* __restrict__ beta, // [C]
118 float* __restrict__ y, // [N, C]
119 int N, int C, int G,
120 float ht_min, float ht_max, float eps
121){
122 const int n = blockIdx.y;
123 const int g = blockIdx.x;
124
125 const int group_size = C / G;
126 const int c0 = g * group_size;
127 const int base = n * C + c0;
128
129 extern __shared__ float smem[];
130 float* sm_vals = smem; // group_size floats for values
131 float* ssum = sm_vals + group_size; // blockDim.x floats for sum
132 float* ssum2 = ssum + blockDim.x; // blockDim.x floats for sum2
133
134 const int tid = threadIdx.x;
135 const int stride = blockDim.x;
136
137 float local_sum = 0.0f;
138 float local_sum2 = 0.0f;
139
140 // Pass 1: compute activation and accumulate sums; keep values in shared memory
141 for (int i = tid; i < group_size; i += stride) {
142 const int c = c0 + i;
143 float v = z[base + i];
144 if (b1) v += b1[c];
145 if (b2) v += b2[c];
146 v = hardtanhf_fast(v, ht_min, ht_max);
147 float m = mishf_fast(v);
148 sm_vals[i] = m;
149 local_sum += m;
150 local_sum2 += m * m;
151 }
152
153 ssum[tid] = local_sum;
154 ssum2[tid] = local_sum2;
155 __syncthreads();
156
157 // Block reduction
158 for (int offset = blockDim.x >> 1; offset > 0; offset >>= 1) {
159 if (tid < offset) {
160 ssum[tid] += ssum[tid + offset];
161 ssum2[tid] += ssum2[tid + offset];
162 }
163 __syncthreads();
164 }
165
166 float mean = ssum[0] / (float)group_size;
167 float var = ssum2[0] / (float)group_size - mean * mean;
168 float rstd = rsqrtf(var + eps);
169
170 // Pass 2: normalize and affine
171 for (int i = tid; i < group_size; i += stride) {
172 const int c = c0 + i;
173 float m = sm_vals[i];
174 float gmul = gamma ? gamma[c] : 1.0f;
175 float gbias = beta ? beta[c] : 0.0f;
176 float gn = (m - mean) * rstd;
177 y[base + i] = gn * gmul + gbias;
178 }
179}
180
181// Persistent group kernel: cache per-channel parameters in shared memory and process a tile of N.
182// Greatly reduces parameter bandwidth when N is large.
183__global__ void fused_bias_act_gn_group_persistent_kernel(
184 const float* __restrict__ z, // [N, C]
185 const float* __restrict__ b1, // [C]
186 const float* __restrict__ b2, // [C]
187 const float* __restrict__ gamma, // [C]
188 const float* __restrict__ beta, // [C]
189 float* __restrict__ y, // [N, C]
190 int N, int C, int G,
191 float ht_min, float ht_max, float eps,
192 int tileN
193){
194 const int g = blockIdx.x;
195 const int group_size = C / G;
196 const int c0 = g * group_size;
197
198 // Tile of batch this block will process
199 const int n_start = blockIdx.y * tileN;
200 const int n_end = min(N, n_start + tileN);
201
202 const int tid = threadIdx.x;
203 const int stride = blockDim.x;
204
205 extern __shared__ float smem[];
206 float* s_bsum = smem; // [group_size]
207 float* s_gamma = s_bsum + group_size; // [group_size]
208 float* s_beta = s_gamma + group_size; // [group_size]
209 float* sm_vals = s_beta + group_size; // [group_size]
210 float* ssum = sm_vals + group_size; // [blockDim.x]
211 float* ssum2 = ssum + blockDim.x; // [blockDim.x]
212
213 // Load per-channel params once per block
214 for (int i = tid; i < group_size; i += stride) {
215 const int c = c0 + i;
216 float bsum = 0.0f;
217 if (b1) bsum += b1[c];
218 if (b2) bsum += b2[c];
219 s_bsum[i] = bsum;
220 s_gamma[i] = gamma ? gamma[c] : 1.0f;
221 s_beta[i] = beta ? beta[c] : 0.0f;
222 }
223 __syncthreads();
224
225 for (int n = n_start; n < n_end; ++n) {
226 const int base = n * C + c0;
227
228 float local_sum = 0.0f;
229 float local_sum2 = 0.0f;
230
231 // Pass 1: load, bias, hardtanh, mish; accumulate stats
232 for (int i = tid; i < group_size; i += stride) {
233 float v = z[base + i] + s_bsum[i];
234 v = hardtanhf_fast(v, ht_min, ht_max);
235 float m = mishf_fast(v);
236 sm_vals[i] = m;
237 local_sum += m;
238 local_sum2 += m * m;
239 }
240
241 ssum[tid] = local_sum;
242 ssum2[tid] = local_sum2;
243 __syncthreads();
244
245 // Reduce sums across block
246 for (int offset = blockDim.x >> 1; offset > 0; offset >>= 1) {
247 if (tid < offset) {
248 ssum[tid] += ssum[tid + offset];
249 ssum2[tid] += ssum2[tid + offset];
250 }
251 __syncthreads();
252 }
253
254 float mean = ssum[0] / (float)group_size;
255 float var = ssum2[0] / (float)group_size - mean * mean;
256 float rstd = rsqrtf(var + eps);
257
258 // Pass 2: groupnorm affine and store
259 for (int i = tid; i < group_size; i += stride) {
260 float gn = (sm_vals[i] - mean) * rstd;
261 y[base + i] = gn * s_gamma[i] + s_beta[i];
262 }
263 __syncthreads();
264 }
265}
266
267torch::Tensor fused_bias_act_groupnorm(
268 torch::Tensor z, // [N, C], float32, CUDA
269 torch::Tensor b1, // [C], float32, CUDA
270 torch::Tensor b2, // [C], float32, CUDA
271 torch::Tensor gamma, // [C], float32, CUDA
272 torch::Tensor beta, // [C], float32, CUDA
273 int64_t G,
274 double ht_min,
275 double ht_max,
276 double eps
277) {
278 CHECK_INPUT_F32(z);
279 CHECK_INPUT_F32(b1);
280 CHECK_INPUT_F32(b2);
281 CHECK_INPUT_F32(gamma);
282 CHECK_INPUT_F32(beta);
283
284 TORCH_CHECK(z.dim() == 2, "z must be 2D (N, C)");
285 int N = (int)z.size(0);
286 int C = (int)z.size(1);
287 TORCH_CHECK((int)gamma.size(0) == C && (int)beta.size(0) == C, "gamma/beta must have size C");
288 TORCH_CHECK((int)b1.size(0) == C && (int)b2.size(0) == C, "b1/b2 must have size C");
289 TORCH_CHECK(C % (int)G == 0, "num_channels must be divisible by num_groups");
290
291 auto y = torch::empty_like(z);
292
293 const int group_size = C / (int)G;
294 dim3 grid((unsigned int)G, (unsigned int)N, 1);
295
296 // Heuristic kernel choice:
297 // - Small groups => warp kernel.
298 // - Otherwise, try persistent group kernel (caches params, processes tile of N).
299 // - Fallback to generic block kernel if shared memory is too large for persistent.
300 bool use_warp = (group_size <= WARP_SIZE) && (N <= 64);
301 if (use_warp) {
302 dim3 block(WARP_SIZE, 1, 1);
303 fused_bias_act_gn_warp_kernel<<<grid, block, 0>>>(
304 z.data_ptr<float>(),
305 b1.data_ptr<float>(),
306 b2.data_ptr<float>(),
307 gamma.data_ptr<float>(),
308 beta.data_ptr<float>(),
309 y.data_ptr<float>(),
310 N, C, (int)G,
311 (float)ht_min, (float)ht_max, (float)eps
312 );
313 } else {
314 // Prefer the persistent kernel to reduce parameter bandwidth when N >= 64.
315 bool prefer_persistent = (N >= 64);
316
317 if (prefer_persistent) {
318 int threads = next_pow2_int(group_size);
319 if (threads > 256) threads = 256;
320 if (threads < 32) threads = 32;
321
322 // Choose a batch tile to get enough blocks while still reusing parameters
323 int tileN;
324 if (N >= 256) tileN = 16;
325 else if (N >= 128) tileN = 8;
326 else if (N >= 64) tileN = 4;
327 else tileN = 2;
328
329 dim3 grid_p((unsigned int)G, (unsigned int)((N + tileN - 1) / tileN), 1);
330 dim3 block((unsigned int)threads, 1, 1);
331
332 // Shared memory: 3*group_size (params) + group_size (vals) + 2*threads (sums)
333 size_t shmem = sizeof(float) * ( (size_t)group_size * 4 + (size_t)threads * 2 );
334
335 // If shared memory too large, fallback to the generic block kernel
336 if (shmem <= 96 * 1024) {
337 fused_bias_act_gn_group_persistent_kernel<<<grid_p, block, shmem>>>(
338 z.data_ptr<float>(),
339 b1.data_ptr<float>(),
340 b2.data_ptr<float>(),
341 gamma.data_ptr<float>(),
342 beta.data_ptr<float>(),
343 y.data_ptr<float>(),
344 N, C, (int)G,
345 (float)ht_min, (float)ht_max, (float)eps,
346 tileN
347 );
348 } else {
349 // Generic block kernel fallback
350 int threads_g = next_pow2_int(group_size);
351 if (threads_g > 256) threads_g = 256;
352 if (threads_g < 64) threads_g = 64;
353 dim3 block_g((unsigned int)threads_g, 1, 1);
354 size_t shmem_g = sizeof(float) * (group_size + threads_g * 2);
355 dim3 grid_g((unsigned int)G, (unsigned int)N, 1);
356
357 fused_bias_act_gn_block_kernel<<<grid_g, block_g, shmem_g>>>(
358 z.data_ptr<float>(),
359 b1.data_ptr<float>(),
360 b2.data_ptr<float>(),
361 gamma.data_ptr<float>(),
362 beta.data_ptr<float>(),
363 y.data_ptr<float>(),
364 N, C, (int)G,
365 (float)ht_min, (float)ht_max, (float)eps
366 );
367 }
368 } else {
369 // Generic block kernel (works for any shape)
370 int threads = next_pow2_int(group_size);
371 if (threads > 256) threads = 256;
372 if (threads < 64) threads = 64;
373 dim3 block((unsigned int)threads, 1, 1);
374 size_t shmem = sizeof(float) * (group_size + threads * 2);
375 dim3 grid_b((unsigned int)G, (unsigned int)N, 1);
376
377 fused_bias_act_gn_block_kernel<<<grid_b, block, shmem>>>(
378 z.data_ptr<float>(),
379 b1.data_ptr<float>(),
380 b2.data_ptr<float>(),
381 gamma.data_ptr<float>(),
382 beta.data_ptr<float>(),
383 y.data_ptr<float>(),
384 N, C, (int)G,
385 (float)ht_min, (float)ht_max, (float)eps
386 );
387 }
388 }
389
390 cudaError_t err = cudaGetLastError();
391 TORCH_CHECK(err == cudaSuccess, "CUDA kernel launch failed: ", cudaGetErrorString(err));
392 return y;
393}
394"""
395
396cpp_src = r"""
397torch::Tensor fused_bias_act_groupnorm(
398 torch::Tensor z,
399 torch::Tensor b1,
400 torch::Tensor b2,
401 torch::Tensor gamma,
402 torch::Tensor beta,
403 int64_t G,
404 double ht_min,
405 double ht_max,
406 double eps
407);
408"""
409
410# Build the extension once
411kernels = load_inline(
412 name="fused_epilogue_gn_kernels_v3",
413 cpp_sources=cpp_src,
414 cuda_sources=cuda_src,
415 functions=["fused_bias_act_groupnorm"],
416 extra_cflags=["-O3"],
417 extra_cuda_cflags=[
418 "-O3",
419 "--use_fast_math",
420 "-Xptxas=-O3,-dlcm=ca" # prefer caching in L2
421 ],
422 verbose=False,
423)
424
425class ModelNew(nn.Module):
426 """
427 Optimized model:
428 - cuBLAS-backed GEMM via F.linear (no bias in GEMM).
429 - Single fused CUDA kernel for: BiasAdd (gemm.bias + extra bias) + Hardtanh + Mish + GroupNorm.
430 - Heuristic kernel chooser:
431 * For small groups and small N: warp kernel (no shared memory).
432 * For larger N: persistent per-group kernel that caches parameters in shared memory and
433 processes a tile of the batch to reduce parameter bandwidth and improve cache locality.
434 * Generic block kernel as a fallback for very large groups or limited shared memory.
435 """
436 def __init__(self, in_features, out_features, bias_shape, num_groups):
437 super().__init__()
438 # Keep bias=True to maintain parameter parity with original, but don't add it in GEMM
439 self.gemm = nn.Linear(in_features, out_features, bias=True)
440 self.bias = nn.Parameter(torch.randn(bias_shape))
441 self.groupnorm = nn.GroupNorm(num_groups=num_groups, num_channels=out_features)
442 self.ht_min = -1.0
443 self.ht_max = 1.0
444
445 @torch.no_grad()
446 def _prepare(self, x):
447 if self.gemm.weight.device != x.device or self.gemm.weight.dtype != x.dtype:
448 self.to(x.device, dtype=x.dtype)
449 # Enable TF32 on tensor cores for GEMM where applicable
450 torch.backends.cuda.matmul.allow_tf32 = True
451 torch.backends.cudnn.allow_tf32 = True
452
453 def forward(self, x):
454 if not x.is_cuda:
455 # CPU fallback path: reference ops
456 z = F.linear(x, self.gemm.weight, bias=None)
457 z = z + self.gemm.bias + self.bias
458 z = torch.clamp(z, min=self.ht_min, max=self.ht_max)
459 z = z * torch.tanh(F.softplus(z))
460 z = self.groupnorm(z)
461 return z
462
463 self._prepare(x)
464
465 # GEMM (no bias here)
466 z = F.linear(x, self.gemm.weight, bias=None)
467
468 # Fused BiasAdd(+gemm.bias + extra bias) + Hardtanh + Mish + GroupNorm
469 y = kernels.fused_bias_act_groupnorm(
470 z.contiguous(),
471 self.gemm.bias.contiguous(),
472 self.bias.contiguous(),
473 self.groupnorm.weight.contiguous(),
474 self.groupnorm.bias.contiguous(),
475 int(self.groupnorm.num_groups),
476 float(self.ht_min),
477 float(self.ht_max),
478 float(self.groupnorm.eps),
479 )
480 return y
481
482
483# Default shapes
484batch_size = 128
485in_features = 512
486out_features = 1024
487bias_shape = (out_features,)
488num_groups = 32
489
490def get_inputs():
491 return [torch.randn(batch_size, in_features, device="cuda", dtype=torch.float32)]
492
493def get_init_inputs():
494 return [in_features, out_features, bias_shape, num_groups]Going back to evaluation, we wanted to look at the subset of KernelBench problems where torch.compile outperformed eager mode in our benchmarking on the H100. These 124 problems are meatier and more representative of cases that we care about optimizing - optimizing a smaller, already-fast module may not provide as much benefit. (Note that the later version of KernelBench includes larger input sizes, which helps mitigate this problem.) When we compare our generated kernels to the subset that’s better on torch.compile, we see that there is still a consistent speedup.

Results for the AI-generated CUDA kernels on the H100, only considering the 124 problems where torch.compile outperformed eager mode execution. We can see for this meatier subset of problems, there is still an average 1.6X speedup for the generated kernels.
In this work, we have been generating CUDA kernels for eager execution. However, in 2 cases, the swarm deviated from eager mode - it actually rewrote the PyTorch code to use torch.compile instead.
For example, on Problem 3, Level 9 (which is a ResNet model), the swarm rewrote the PyTorch code to create a fused implementation in Python, only dropping down to CUDA for a few operations. Then it wrapped this fused PyTorch implementation in torch.compile so torch.compile could handle the fusion. This approach achieved an 1.66X speedup over torch.compile and a 2.1X speedup over eager mode.
ResNet18 (Level 3 Problem 9)
1import torch
2import torch.nn as nn
3import torch.nn.functional as F
4
5class BasicBlock(nn.Module):
6 expansion = 1
7
8 def __init__(self, in_channels, out_channels, stride=1, downsample=None):
9 """
10 :param in_channels: Number of input channels
11 :param out_channels: Number of output channels
12 :param stride: Stride for the first convolutional layer
13 :param downsample: Downsample layer for the shortcut connection
14 """
15 super(BasicBlock, self).__init__()
16 self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
17 self.bn1 = nn.BatchNorm2d(out_channels)
18 self.relu = nn.ReLU(inplace=True)
19 self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
20 self.bn2 = nn.BatchNorm2d(out_channels)
21 self.downsample = downsample
22 self.stride = stride
23
24 def forward(self, x):
25 """
26 :param x: Input tensor, shape (batch_size, in_channels, height, width)
27 :return: Output tensor, shape (batch_size, out_channels, height, width)
28 """
29 identity = x
30
31 out = self.conv1(x)
32 out = self.bn1(out)
33 out = self.relu(out)
34
35 out = self.conv2(out)
36 out = self.bn2(out)
37
38 if self.downsample is not None:
39 identity = self.downsample(x)
40
41 out += identity
42 out = self.relu(out)
43
44 return out
45
46class Model(nn.Module):
47 def __init__(self, num_classes=1000):
48 """
49 :param num_classes: Number of output classes
50 """
51 super(Model, self).__init__()
52 self.in_channels = 64
53
54 self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
55 self.bn1 = nn.BatchNorm2d(64)
56 self.relu = nn.ReLU(inplace=True)
57 self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
58
59 self.layer1 = self._make_layer(BasicBlock, 64, 2, stride=1)
60 self.layer2 = self._make_layer(BasicBlock, 128, 2, stride=2)
61 self.layer3 = self._make_layer(BasicBlock, 256, 2, stride=2)
62 self.layer4 = self._make_layer(BasicBlock, 512, 2, stride=2)
63
64 self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
65 self.fc = nn.Linear(512 * BasicBlock.expansion, num_classes)
66
67 def _make_layer(self, block, out_channels, blocks, stride=1):
68 downsample = None
69 if stride != 1 or self.in_channels != out_channels * block.expansion:
70 downsample = nn.Sequential(
71 nn.Conv2d(self.in_channels, out_channels * block.expansion, kernel_size=1, stride=stride, bias=False),
72 nn.BatchNorm2d(out_channels * block.expansion),
73 )
74
75 layers = []
76 layers.append(block(self.in_channels, out_channels, stride, downsample))
77 self.in_channels = out_channels * block.expansion
78 for _ in range(1, blocks):
79 layers.append(block(self.in_channels, out_channels))
80
81 return nn.Sequential(*layers)
82
83 def forward(self, x):
84 """
85 :param x: Input tensor, shape (batch_size, 3, height, width)
86 :return: Output tensor, shape (batch_size, num_classes)
87 """
88 x = self.conv1(x)
89 x = self.bn1(x)
90 x = self.relu(x)
91 x = self.maxpool(x)
92
93 x = self.layer1(x)
94 x = self.layer2(x)
95 x = self.layer3(x)
96 x = self.layer4(x)
97
98 x = self.avgpool(x)
99 x = torch.flatten(x, 1)
100 x = self.fc(x)
101
102 return x
103
104# Test code
105batch_size = 2
106num_classes = 1000
107input_shape = (batch_size, 3, 224, 224)
108
109def get_inputs():
110 return [torch.randn(input_shape)]
111
112def get_init_inputs():
113 return [num_classes]1import torch
2import torch.nn as nn
3import torch.nn.functional as F
4from torch.utils.cpp_extension import load_inline
5
6# Custom CUDA kernel for Add+ReLU (channels-last)
7add_relu_cuda_src = """
8#include <torch/extension.h>
9#include <cuda_runtime.h>
10
11__global__ void add_relu_kernel(const float* a, const float* b, float* out, int size) {
12 int idx = blockIdx.x * blockDim.x + threadIdx.x;
13 if (idx < size) {
14 float val = a[idx] + b[idx];
15 out[idx] = val > 0.0f ? val : 0.0f;
16 }
17}
18
19torch::Tensor add_relu_cuda(torch::Tensor a, torch::Tensor b) {
20 auto size = a.numel();
21 auto out = torch::empty_like(a);
22
23 const int block_size = 256;
24 const int num_blocks = (size + block_size - 1) / block_size;
25
26 add_relu_kernel<<<num_blocks, block_size>>>(
27 a.data_ptr<float>(), b.data_ptr<float>(), out.data_ptr<float>(), size
28 );
29
30 return out;
31}
32"""
33
34add_relu_cpp_src = "torch::Tensor add_relu_cuda(torch::Tensor a, torch::Tensor b);"
35
36add_relu = load_inline(
37 name="add_relu",
38 cpp_sources=add_relu_cpp_src,
39 cuda_sources=add_relu_cuda_src,
40 functions=["add_relu_cuda"],
41 verbose=False,
42)
43
44# Helper to fold BN into Conv2d (for inference)
45def fuse_conv_bn(conv, bn):
46 # Only for inference!
47 assert not conv.training and not bn.training
48 fused_conv = nn.Conv2d(
49 conv.in_channels,
50 conv.out_channels,
51 conv.kernel_size,
52 conv.stride,
53 conv.padding,
54 conv.dilation,
55 conv.groups,
56 bias=True,
57 device=conv.weight.device,
58 dtype=conv.weight.dtype,
59 )
60 # Prepare parameters
61 w_conv = conv.weight
62 if conv.bias is not None:
63 b_conv = conv.bias
64 else:
65 b_conv = torch.zeros(conv.weight.size(0), device=w_conv.device, dtype=w_conv.dtype)
66 w_bn = bn.weight
67 b_bn = bn.bias
68 mean = bn.running_mean
69 var = bn.running_var
70 eps = bn.eps
71
72 std = torch.sqrt(var + eps)
73 w_bn = w_bn / std
74 fused_conv.weight.data = w_conv * w_bn.reshape([-1, 1, 1, 1])
75 fused_conv.bias.data = (b_conv - mean) / std * bn.weight + bn.bias
76
77 # Set channels-last for weights
78 fused_conv.weight.data = fused_conv.weight.data.contiguous(memory_format=torch.channels_last)
79 fused_conv.bias.data = fused_conv.bias.data.contiguous()
80 return fused_conv
81
82# Fused Conv+BN+ReLU module (for inference)
83class FusedConvBNReLU(nn.Module):
84 def __init__(self, conv, bn, relu=True):
85 super().__init__()
86 self.relu = relu
87 self.fused_conv = fuse_conv_bn(conv, bn)
88 self.fused_conv.weight.requires_grad = False
89 self.fused_conv.bias.requires_grad = False
90
91 def forward(self, x):
92 x = self.fused_conv(x)
93 if self.relu:
94 return F.relu(x)
95 else:
96 return x
97
98# Fused Add+ReLU module
99class AddReLUFunction(torch.autograd.Function):
100 @staticmethod
101 def forward(ctx, a, b):
102 return add_relu.add_relu_cuda(a, b)
103
104 @staticmethod
105 def backward(ctx, grad_output):
106 # Not needed for inference
107 return grad_output, grad_output
108
109class AddReLU(nn.Module):
110 def forward(self, a, b):
111 return AddReLUFunction.apply(a, b)
112
113# Fused MaxPool+Conv+BN+ReLU for stem
114class FusedStem(nn.Module):
115 def __init__(self, conv, bn, relu, maxpool):
116 super().__init__()
117 self.maxpool = maxpool
118 self.fused_conv = fuse_conv_bn(conv, bn)
119 self.fused_conv.weight.requires_grad = False
120 self.fused_conv.bias.requires_grad = False
121
122 def forward(self, x):
123 x = self.fused_conv(x)
124 x = F.relu(x)
125 x = self.maxpool(x)
126 return x
127
128# Downsample block with fusion
129class DownsampleNew(nn.Module):
130 def __init__(self, in_channels, out_channels, stride):
131 super().__init__()
132 self._conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False)
133 self._bn = nn.BatchNorm2d(out_channels)
134 self.conv = None
135
136 def fuse(self):
137 self.conv = FusedConvBNReLU(self._conv, self._bn, relu=False)
138
139 def forward(self, x):
140 if self.conv is not None:
141 return self.conv(x)
142 else:
143 return self._bn(self._conv(x))
144
145# Optimized BasicBlock with fused ops and channels-last
146class BasicBlockNew(nn.Module):
147 expansion = 1
148
149 def __init__(self, in_channels, out_channels, stride=1, downsample=None):
150 super().__init__()
151 self.stride = stride
152 self.downsample = downsample
153
154 self.conv1 = None
155 self.conv2 = None
156
157 self._conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
158 self._bn1 = nn.BatchNorm2d(out_channels)
159 self._conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
160 self._bn2 = nn.BatchNorm2d(out_channels)
161 self.relu = nn.ReLU(inplace=False)
162 self.add_relu = AddReLU()
163
164 # Set channels-last for weights
165 self._conv1.weight.data = self._conv1.weight.data.contiguous(memory_format=torch.channels_last)
166 self._conv2.weight.data = self._conv2.weight.data.contiguous(memory_format=torch.channels_last)
167
168 def fuse(self):
169 # Call this after loading weights and switching to eval()
170 self.conv1 = FusedConvBNReLU(self._conv1, self._bn1, relu=True)
171 self.conv2 = FusedConvBNReLU(self._conv2, self._bn2, relu=False)
172 if self.downsample is not None and hasattr(self.downsample, "fuse"):
173 self.downsample.fuse()
174
175 def forward(self, x):
176 identity = x
177
178 if self.conv1 is not None:
179 out = self.conv1(x)
180 out = self.conv2(out)
181 else:
182 out = self._conv1(x)
183 out = self._bn1(out)
184 out = self.relu(out)
185 out = self._conv2(out)
186 out = self._bn2(out)
187
188 if self.downsample is not None:
189 identity = self.downsample(x)
190
191 if self.conv1 is not None:
192 out = self.add_relu(out, identity)
193 else:
194 out = out + identity
195 out = self.relu(out)
196
197 return out
198
199# Optimized Model
200class ModelNew(nn.Module):
201 def __init__(self, num_classes=1000):
202 super().__init__()
203 self.in_channels = 64
204
205 self._conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
206 self._bn1 = nn.BatchNorm2d(64)
207 self.relu = nn.ReLU(inplace=False)
208 self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
209
210 # Set channels-last for stem weights
211 self._conv1.weight.data = self._conv1.weight.data.contiguous(memory_format=torch.channels_last)
212
213 self.layer1 = self._make_layer(BasicBlockNew, 64, 2, stride=1)
214 self.layer2 = self._make_layer(BasicBlockNew, 128, 2, stride=2)
215 self.layer3 = self._make_layer(BasicBlockNew, 256, 2, stride=2)
216 self.layer4 = self._make_layer(BasicBlockNew, 512, 2, stride=2)
217
218 self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
219 self.fc = nn.Linear(512 * BasicBlockNew.expansion, num_classes)
220
221 self.stem = None
222
223 def fuse(self):
224 # Call this after loading weights and switching to eval()
225 self.stem = FusedStem(self._conv1, self._bn1, self.relu, self.maxpool)
226 for m in self.modules():
227 if hasattr(m, "fuse"):
228 m.fuse()
229
230 def _make_layer(self, block, out_channels, blocks, stride=1):
231 downsample = None
232 if stride != 1 or self.in_channels != out_channels * block.expansion:
233 downsample = DownsampleNew(self.in_channels, out_channels * block.expansion, stride)
234
235 layers = []
236 layers.append(block(self.in_channels, out_channels, stride, downsample))
237 self.in_channels = out_channels * block.expansion
238 for _ in range(1, blocks):
239 layers.append(block(self.in_channels, out_channels))
240
241 return nn.Sequential(*layers)
242
243 def forward(self, x):
244 # Use channels-last for input
245 x = x.to(memory_format=torch.channels_last)
246 if self.stem is not None:
247 x = self.stem(x)
248 else:
249 x = self._conv1(x)
250 x = self._bn1(x)
251 x = self.relu(x)
252 x = self.maxpool(x)
253
254 x = self.layer1(x)
255 x = self.layer2(x)
256 x = self.layer3(x)
257 x = self.layer4(x)
258
259 x = self.avgpool(x)
260 x = torch.flatten(x, 1)
261 x = self.fc(x)
262
263 return x
264
265# Compile the model for further fusion (PyTorch 2.0+)
266try:
267 import torch._dynamo
268 ModelNew = torch.compile(ModelNew, mode="reduce-overhead")
269except Exception:
270 pass # torch.compile not available, fallback to normal classAs seen from this case, AI kernel generation and optimizations like torch.compile have the potential to be complementary when used together. The goal is to get faster PyTorch performance using any techniques available, not focus exclusively on any one technique. Generating low-level kernels alongside calls to torch.compile will generate the best result in many cases.
What’s next?
One common question with performance optimization - whether it’s done by a human or AI - is the upper limit on the gains you can achieve. In order to answer this question rigorously, we can use the roofline model as a tool. The roofline model helps us understand the theoretical maximum performance of a given workload, based on its arithmetic intensity - the ratio of operations performed to bytes of memory accessed. Compute-bound workloads have high arithmetic intensity and can (in theory) go as fast as the max compute capability of the GPU, whereas memory-bound workloads have low arithmetic intensity and cannot saturate the GPU's compute resources because memory bandwidth becomes the bottleneck. ```
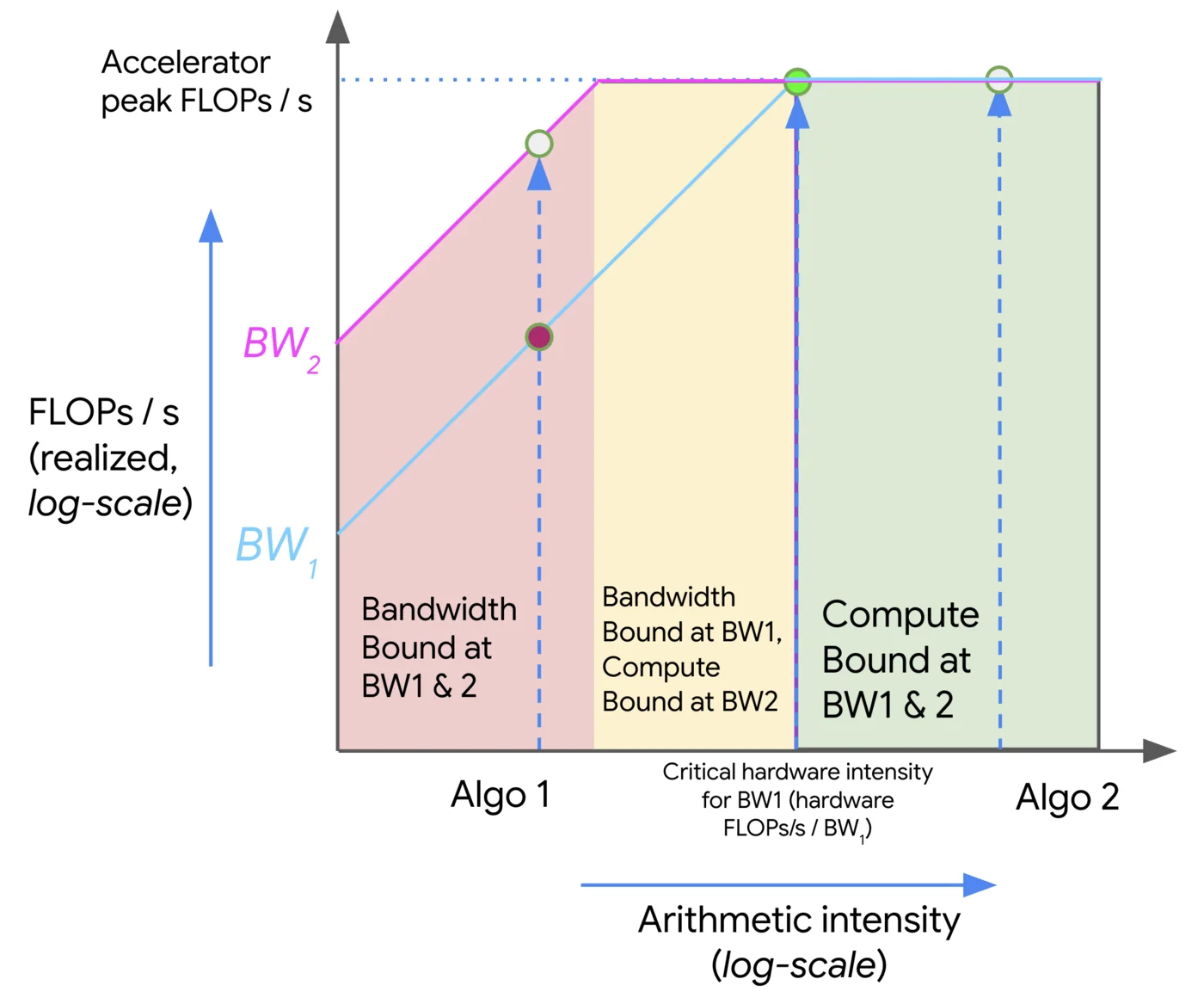
Depiction of a roofline model. We can see that compute-bound workloads can achieve the maximum FLOPs on a given accelerator, but memory-bound workloads cannot. Source: Google DeepMind.
We are incorporating roofline models into this work. They are very useful when characterizing workloads and understanding how far off baseline performance is from theoretical best performance, and which resource the workload is bound by (e.g. compute, bandwidth, etc). These models will guide the agentic swarm to perform better optimization of the underlying kernels.
We’ll continue to expand this research in other directions, too - more use cases, more models, more target hardware platforms, supporting backward passes for training - in order to achieve the goal of autonomously improving model performance. If you’re interested in this topic, give us a shout at hello@gimletlabs.ai.
Footnotes
We will be comparing against the newer version of KernelBench in subsequent posts. ↩
Arithmetic means will artificially inflate results when comparing averages of speedups. For example, if you have two speedups - 0.5X and 2X, the arithmetic mean of them will be 1.25X - even though one doubled the speed and one halved it. To account for this, the geometric mean is the typical approach. In a geometric mean, the average of 0.5 and 2 will be 1. ↩
We compare against the default
torch.compilemode here, but it would be interesting to compare againsttorch.compilewith the different configuration options - e.g.max-autotune. ↩