Designing infrastructure for running efficient AI workloads
- Published on
- Authors

- Name
- Michelle Nguyen

- Name
- Zain Asgar
Designing infrastructure for running efficient AI workloads
Introduction
AI workloads are rapidly evolving from single LLM inference calls to complex, multi-model systems. These workloads aren’t just bigger; they’re more diverse, spanning operations from large scale inference to lightweight API calls. While it’s critical to run large LLMs efficiently, delivering end-to-end performance requires thinking holistically about the entire workflow. This work explores the makeup of AI workloads and the systems needed to support them at scale.
What do AI workloads look like?
The workflow for every AI agent is different, shaped by varying levels of autonomy, interactivity, and external capabilities such as tool or API calls. The flow is inherently dynamic, as an agent will take whatever path it needs to achieve its goal, navigating through non-linear steps, backtracking, or branching paths.
These characteristics mean workloads can vary widely in size, complexity, and sensitivity to different resources. For example, LLM inference is dominated by large matrix multiplications, requiring high performance compute, memory bandwidth to move data quickly, and sufficient capacity to hold model weights. In contrast, tool calls have a very different profile. Performance depends on network throughput and general purpose compute, but has little need for specialized compute since the heavy lifting occurs externally. AI workloads will only become more diverse as builders continue to uncover new ways to apply AI.
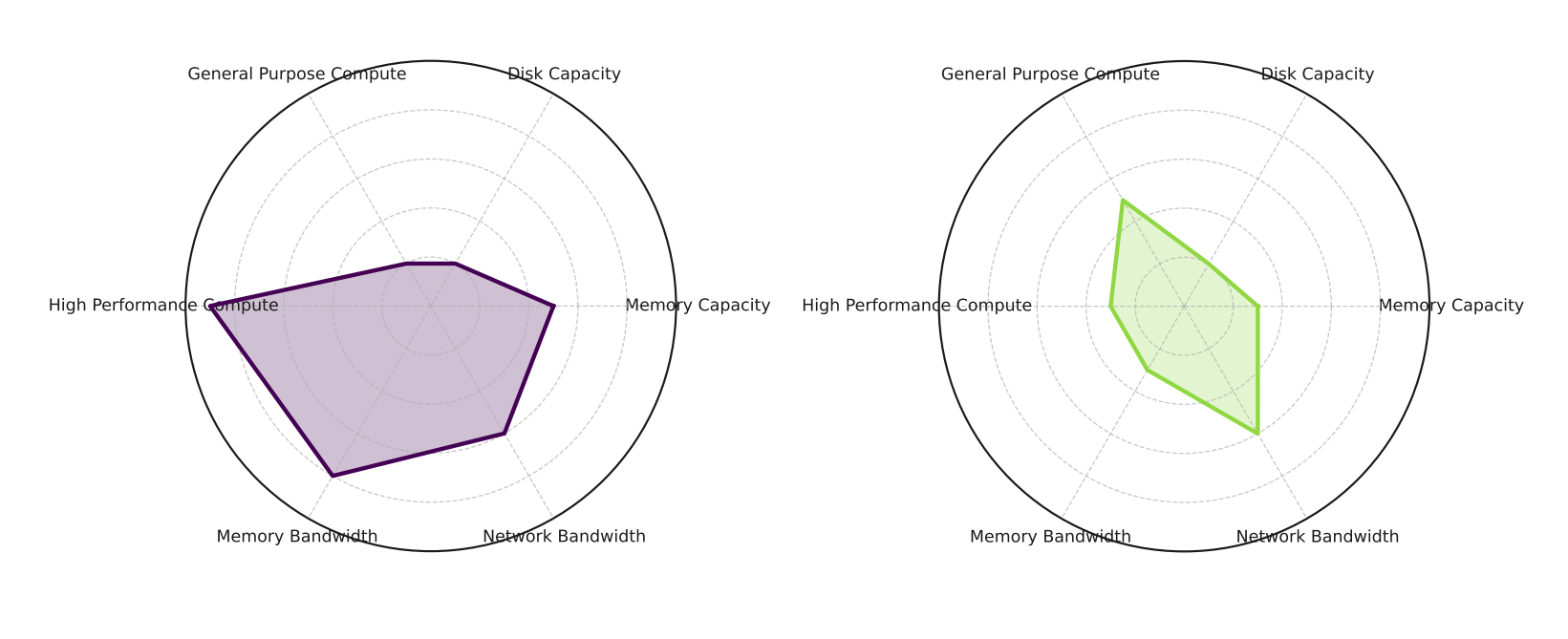
Resource sensitivities of model execution (left) and tool calls (right). Note, these are just ballpark estimates of each operation’s tendencies, this can vary based on specifics of the task itself. We explore the profiles of more tasks in detail in Source: Asgar et al.
How can we execute AI workloads efficiently?
At Gimlet, our goal is to figure out how to best execute AI workloads on the available hardware. This starts with understanding the workloads, and representing them in a way where we can systematically optimize them for execution on the targets. We believe to make this process tractable, these workloads are best expressed as dataflow graphs, where nodes represent work to be done and edges capture dependencies and data movement. With this representation, even complex multi-agent hierarchies can be abstracted to high level graphs, as illustrated by LangGraph.
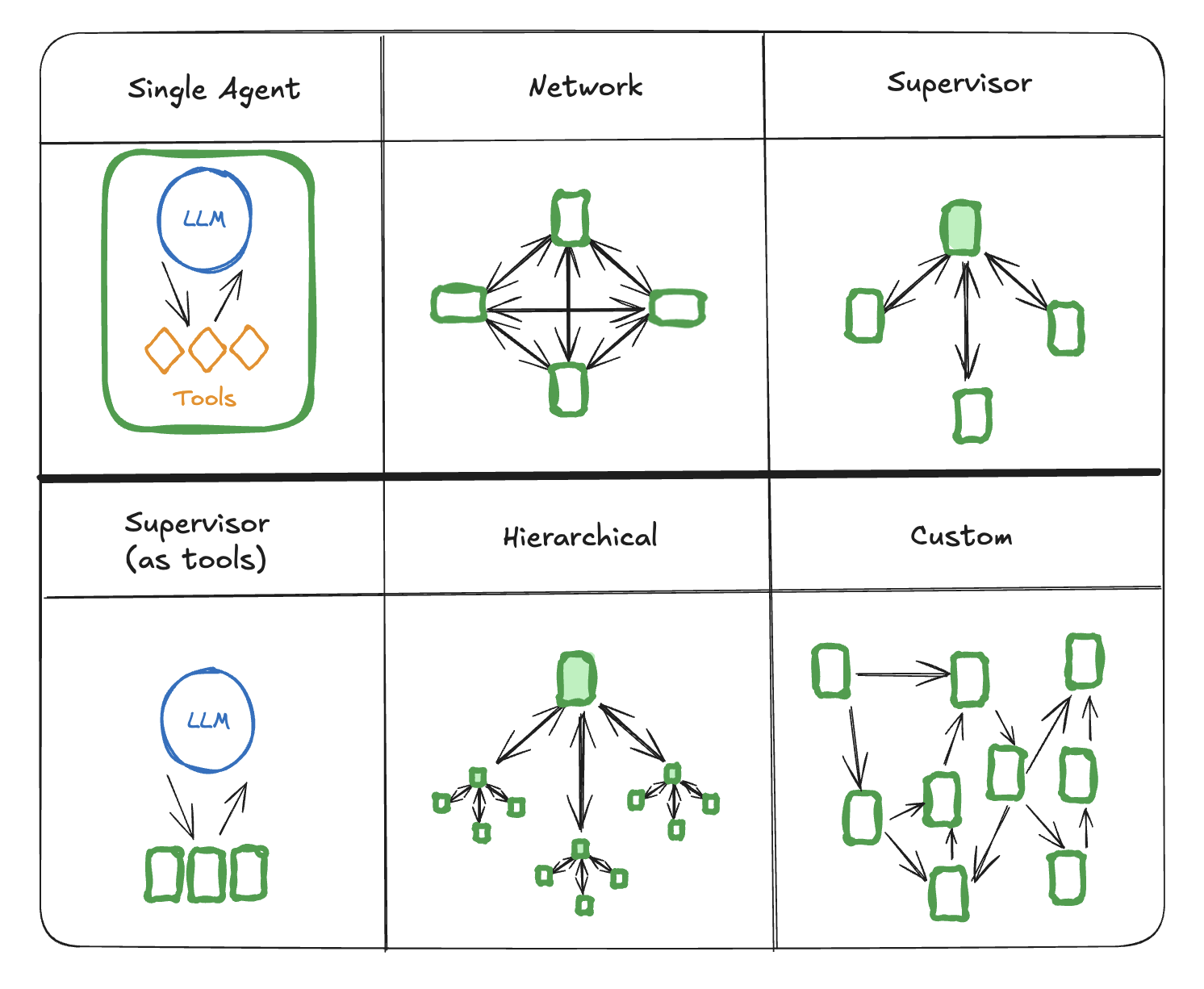
LangGraph’s summary of architectural patterns for multi-agent workflows. Source: LangGraph.
Once workloads are expressed as graphs, execution becomes a matter of mapping nodes to the right hardware. On one side, we have nodes with very different computational profiles. For example, a large LLM inference node is best suited to high performance GPUs, while lighter weight tasks, such as API calls, may run efficiently on CPUs. On the other side, we have a diverse set of hardware resources with their own costs, strengths, and constraints across compute, memory, and networking. This optimization can be taken a step further by breaking down nodes into even more granular steps for more efficiency. For instance, we dive into how LLM inference can be partitioned and scheduled as separate prefill and decode phases across two different accelerators to maximize performance and cost efficiency. At scale, these optimizations improve hardware utilization and significantly reduce the overall cost of running AI workloads. Making this possible requires infrastructure that can effectively perform and execute these graph optimizations.
What’s needed to run AI workloads at datacenter scale?
Running agentic workloads at scale requires a system that can decompose workloads, map them to the right hardware, and optimize their execution across heterogeneous environments spanning CPUs and GPUs, within and across vendors. The challenge is that these mappings are never static. The system must adapt to changing hardware availability, balance efficiency across SLAs, and adjust as usage patterns evolve. To achieve this, we need an execution stack designed to make dynamic decisions in real time. We believe the stack should be built around a set of connected components addressing different layers of the execution flow.
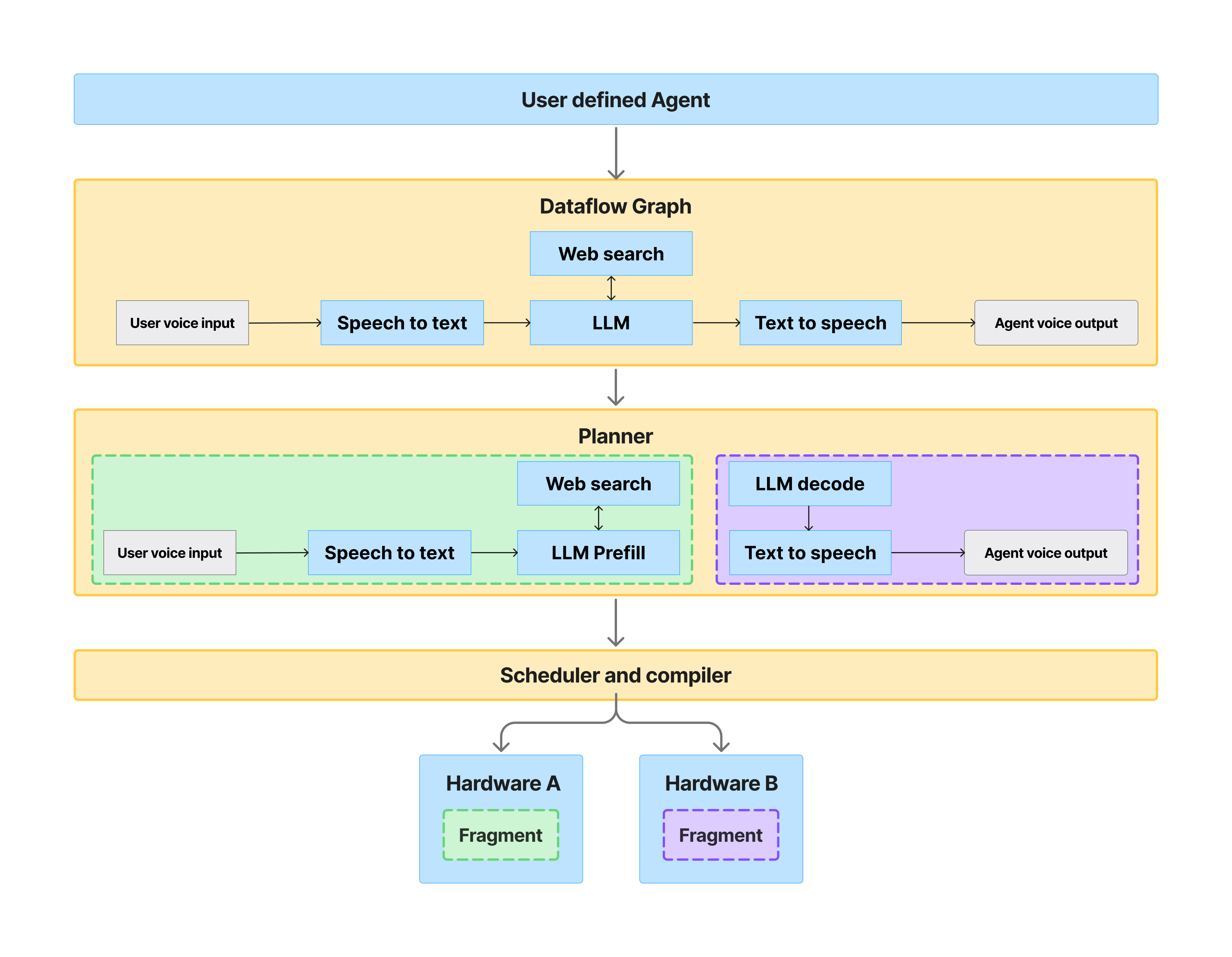
System for dynamically decomposing workloads, planning, scheduling, and optimizing hardware across heterogeneous environments.
- AI Agent Definition: Users should be able to define their workloads through popular tools like Huggingface or Langchain. Under the hood, these workloads need to be expressed in a common representation that can capture the dynamic graph structures of these AI workloads. This abstraction gives us the ability to analyze, reason about, and adapt workloads in a structured way.
- Distillation Engine: Even after workloads have been defined, there are still opportunities to adapt the models to improve cost, latency, and performance. Distillation allows us to shrink models to better fit the application’s use case and improve efficiency while preserving accuracy.
- Planner: Given the workflow graph and the characteristics of its nodes and edges, we need a way to break it down into smaller, schedulable units of work. These partitions expose natural boundaries, for example, splitting LLM inference into prefill and decode phases, to enable finer-grained execution.
- Scheduler: Once the graph is partitioned, we need a system that can optimize placement of each fragment on available hardware. Placement should account for characteristics of the task and hardware, as well as system constraints such as locality and resource availability.
- Compiler: After scheduling, fragments must be lowered and optimized for the target hardware. The compiler handles translation, applying techniques like operator fusion, parallelism strategies, and kernel generation to maximize performance.
These elements are just outlined in brief. However, we’ve already shared some details about different parts of this stack, from disaggregating LLM inference across different accelerators to allocate inference for cost efficiency, to automatic kernel generation to ensure optimal performance across any hardware. We also discuss this in more technical detail in a paper.
Together, these components provide the foundation for running agentic workloads seamlessly and cost effectively across heterogeneous hardware.
Next Steps
At Gimlet, we’re tackling every part of the stack, from a universal AI compiler for device aware compute graphs, to cost driven optimization for efficient execution. The growth of AI is only accelerating, and we believe this is the path to running it faster and more sustainably. As these workloads continue to grow in scale and complexity, heterogenous systems won’t just be an advantage, but the foundation for the future of AI inference. We’re excited to help make that future a reality, and will continue sharing more as we learn along the way.